- FONCTIONS (REPRÉSENTATION ET APPROXIMATION DES)
- FONCTIONS (REPRÉSENTATION ET APPROXIMATION DES)Il arrive très souvent que, dans les problèmes issus des mathématiques ou des autres sciences, les fonctions qui interviennent soient définies par des procédés qui ne permettent pas d’étudier de manière efficace leurs propriétés. C’est le cas des fonctions définies comme solutions d’équations fonctionnelles, d’équations différentielles ou intégrales, d’équations aux dérivées partielles, ou encore de problèmes variationnels. Ainsi, les fonctions exponentielles sont les solutions suffisamment régulières de l’équation fonctionnelle f (x + y ) = f (x )f (y ), ou encore de l’équation différentielle f (x ) = af (x ).On essaie alors de représenter une telle fonction f sous une forme plus efficace pour l’étude du problème posé (existence et unicité, variation de f , comportement asymptotique, dépendance de paramètres, approximation numérique, prolongement analytique...).Quelques grandes méthodes se sont progressivement dégagées.Il s’agit en premier lieu des représentations continues , obtenues à l’aide du calcul intégral. Dès le XVIIe siècle, le calcul des primitives a été utilisé pour représenter certaines fonctions. Ainsi, la fonction logarithme satisfait au problème de Cauchy g (t ) = 1/t , g (1) = 0, d’où:
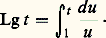 Cette relation permet de prouver l’existence du logarithme et, par suite, de l’exponentielle, ainsi que leur variation et leur comportement à l’infini [cf. EXPONENTIELLE ET LOGARITHME]. Les représentations intégrales interviennent aussi sous la forme d’intégrales dépendant de paramètres, introduites par Leibniz. Les transformations de Fourier et de Laplace sont de ce type.Il s’agit en second lieu des représentations discrètes et, au premier chef, des développements en série entière . Ainsi, la recherche des solutions sur R du problème de Cauchy y = y , y (0) = 1, sous forme de série entière conduit à l’expression:
Cette relation permet de prouver l’existence du logarithme et, par suite, de l’exponentielle, ainsi que leur variation et leur comportement à l’infini [cf. EXPONENTIELLE ET LOGARITHME]. Les représentations intégrales interviennent aussi sous la forme d’intégrales dépendant de paramètres, introduites par Leibniz. Les transformations de Fourier et de Laplace sont de ce type.Il s’agit en second lieu des représentations discrètes et, au premier chef, des développements en série entière . Ainsi, la recherche des solutions sur R du problème de Cauchy y = y , y (0) = 1, sous forme de série entière conduit à l’expression: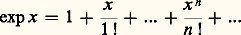 Cette expression fournit l’existence de la fonction exponentielle et une approximation polynomiale par majoration du reste. Combinée avec l’équation fonctionnelle, elle permet aussi de calculer des valeurs approchées en un point; elle permet encore de prouver que la fonction exponentielle est prépondérante au voisinage de + 秊 sur les fonctions puissance; enfin, elle permet le prolongement analytique au plan complexe par:
Cette expression fournit l’existence de la fonction exponentielle et une approximation polynomiale par majoration du reste. Combinée avec l’équation fonctionnelle, elle permet aussi de calculer des valeurs approchées en un point; elle permet encore de prouver que la fonction exponentielle est prépondérante au voisinage de + 秊 sur les fonctions puissance; enfin, elle permet le prolongement analytique au plan complexe par: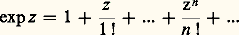 On peut alors étudier les solutions sur [0, + 秊[ du problème de Cauchy y = ay , y (0) =, où et a sont des nombres complexes, et établir la condition de stabilité en fonction du paramètre a , à savoir Rea 麗 0.Selon les problèmes, on est amené à utiliser d’autres types de séries: séries de Fourier pour les phénomènes périodiques, séries de polynômes orthogonaux...On peut aussi utiliser des procédés d’approximation par des suites de fonctions . Ainsi, la méthode du pas à pas d’Euler et Cauchy (cf. équations DIFFÉRENTIELLES, chap. 7), appliquée à l’équation différentielle y = y , y (0) = 1, conduit à la relation:
On peut alors étudier les solutions sur [0, + 秊[ du problème de Cauchy y = ay , y (0) =, où et a sont des nombres complexes, et établir la condition de stabilité en fonction du paramètre a , à savoir Rea 麗 0.Selon les problèmes, on est amené à utiliser d’autres types de séries: séries de Fourier pour les phénomènes périodiques, séries de polynômes orthogonaux...On peut aussi utiliser des procédés d’approximation par des suites de fonctions . Ainsi, la méthode du pas à pas d’Euler et Cauchy (cf. équations DIFFÉRENTIELLES, chap. 7), appliquée à l’équation différentielle y = y , y (0) = 1, conduit à la relation: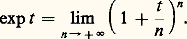 De même, la méthode des approximations successives de Cauchy-Picard (cf. équations DIFFÉRENTIELLES, chap. 1), appliquée à cette même équation, fournit à nouveau le développement en série de la fonction exponentielle.Au XVIIIe siècle, les problèmes de représentation et d’approximation sont étudiés dans le cadre formel, le passage au domaine numérique étant traité de façon purement expérimentale, tandis qu’au XIXe siècle, les problèmes de convergence jouent un rôle central ainsi que la validité des opérations sur les représentations utilisées (opérations algébriques, dérivation, intégration, sommation...).Les problèmes numériques conduisent à étudier non seulement la convergence mais aussi la vitesse de convergence et la stabilité. Ces nouvelles préoccupations conduisent, à la fin du XIXe siècle, à diversifier les modes de convergence , à diversifier les objets par lesquels on approche les fonctions et à rechercher des procédés optimaux . L’ensemble des travaux sur ce sujet a joué un rôle moteur dans la constitution de l’analyse fonctionnelle au début du XXe siècle.Enfin, dans les problèmes d’approximation, il arrive souvent qu’on veuille approcher non pas une fonction f mais la valeur sur f d’une forme linéaire donnée: intégrale de f , valeur de f ou d’une de ses dérivées en un point, coefficients de Fourier d’une fonction périodique f ... Pour ce type de question, on se ramène bien entendu à approcher f par des fonctions plus simples, mais, ici, le point de vue est différent car l’étude de la rapidité de convergence et de l’optimisation sont spécifiques de la forme linéaire considérée (cf. analyse NUMÉRIQUE chap. 2).L’enseignement de ces questions en France est conçu selon un plan rigide: étude des modes de convergence dans un cadre abstrait, validation des opérations sur les séries et les intégrales, représentation des fonctions et, enfin, résolution de problèmes. Cette démarche est contraire à la pratique scientifique où l’approfondissement théorique des modes de représentation et d’approximation va de pair avec l’étude des problèmes visés.Les méthodes de représentation et d’approximation jouent un rôle central dans l’analyse mathématique. Elles sont présentées de façon synthétique dans les cinq premiers chapitres, qui renvoient pour plus de détails sur chacune des méthodes décrites aux divers articles d’analyse de l’Encyclopédie. Dans les trois derniers chapitres, nous approfondissons les problèmes d’approximation en abordant notamment les questions de stabilité et de vitesse de convergence, spécialement utiles en analyse numérique.1. Convergences usuelles en analysePour traiter des problèmes de représentation et d’approximation des fonctions, il est indispensable de préciser ce que l’on entend par l’écart de deux fonctions. Dans les cas les plus simples, on peut définir cet écart à l’aide d’une norme sur l’espace vectoriel E de fonctions considéré (cf. espaces vectoriels NORMÉS).Normes usuellesConsidérons d’abord l’espace vectoriel 暈([a , b ]) des fonctions continues à valeurs complexes sur un intervalle I = [a , b ].Les trois normes usuelles sont:– la norme de la convergence uniforme :
De même, la méthode des approximations successives de Cauchy-Picard (cf. équations DIFFÉRENTIELLES, chap. 1), appliquée à cette même équation, fournit à nouveau le développement en série de la fonction exponentielle.Au XVIIIe siècle, les problèmes de représentation et d’approximation sont étudiés dans le cadre formel, le passage au domaine numérique étant traité de façon purement expérimentale, tandis qu’au XIXe siècle, les problèmes de convergence jouent un rôle central ainsi que la validité des opérations sur les représentations utilisées (opérations algébriques, dérivation, intégration, sommation...).Les problèmes numériques conduisent à étudier non seulement la convergence mais aussi la vitesse de convergence et la stabilité. Ces nouvelles préoccupations conduisent, à la fin du XIXe siècle, à diversifier les modes de convergence , à diversifier les objets par lesquels on approche les fonctions et à rechercher des procédés optimaux . L’ensemble des travaux sur ce sujet a joué un rôle moteur dans la constitution de l’analyse fonctionnelle au début du XXe siècle.Enfin, dans les problèmes d’approximation, il arrive souvent qu’on veuille approcher non pas une fonction f mais la valeur sur f d’une forme linéaire donnée: intégrale de f , valeur de f ou d’une de ses dérivées en un point, coefficients de Fourier d’une fonction périodique f ... Pour ce type de question, on se ramène bien entendu à approcher f par des fonctions plus simples, mais, ici, le point de vue est différent car l’étude de la rapidité de convergence et de l’optimisation sont spécifiques de la forme linéaire considérée (cf. analyse NUMÉRIQUE chap. 2).L’enseignement de ces questions en France est conçu selon un plan rigide: étude des modes de convergence dans un cadre abstrait, validation des opérations sur les séries et les intégrales, représentation des fonctions et, enfin, résolution de problèmes. Cette démarche est contraire à la pratique scientifique où l’approfondissement théorique des modes de représentation et d’approximation va de pair avec l’étude des problèmes visés.Les méthodes de représentation et d’approximation jouent un rôle central dans l’analyse mathématique. Elles sont présentées de façon synthétique dans les cinq premiers chapitres, qui renvoient pour plus de détails sur chacune des méthodes décrites aux divers articles d’analyse de l’Encyclopédie. Dans les trois derniers chapitres, nous approfondissons les problèmes d’approximation en abordant notamment les questions de stabilité et de vitesse de convergence, spécialement utiles en analyse numérique.1. Convergences usuelles en analysePour traiter des problèmes de représentation et d’approximation des fonctions, il est indispensable de préciser ce que l’on entend par l’écart de deux fonctions. Dans les cas les plus simples, on peut définir cet écart à l’aide d’une norme sur l’espace vectoriel E de fonctions considéré (cf. espaces vectoriels NORMÉS).Normes usuellesConsidérons d’abord l’espace vectoriel 暈([a , b ]) des fonctions continues à valeurs complexes sur un intervalle I = [a , b ].Les trois normes usuelles sont:– la norme de la convergence uniforme :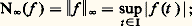 – la norme de la convergence en moyenne :
– la norme de la convergence en moyenne :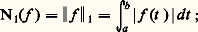 – la norme de la convergence en moyenne quadratique :
– la norme de la convergence en moyenne quadratique :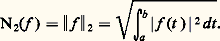 Soit f une fonction positive. Cette fonction f est petite au sens de la norme N size=1秊 si elle est petite partout; cela signifie que son graphe est contenu dans une bande de hauteur petite (cf. fig. 1). La fonction f est petite au sens de la norme 1 si l’aire de la partie hachurée sur la figure 2 est petite. Le cas de la norme 2 s’y ramène en considérant la fonction f 2.Il apparaît aussitôt que si f est petite pour N size=1秊, elle est aussi petite pour 1 et 2 (si l’intervalle I n’est pas trop grand, cela va sans dire...), mais f peut fort bien être petite pour 1 sans l’être pour N size=1秊 (phénomène de «pointe», fig. 2). Mathématiquement, ces considérations peuvent être précisées par les inégalités:
Soit f une fonction positive. Cette fonction f est petite au sens de la norme N size=1秊 si elle est petite partout; cela signifie que son graphe est contenu dans une bande de hauteur petite (cf. fig. 1). La fonction f est petite au sens de la norme 1 si l’aire de la partie hachurée sur la figure 2 est petite. Le cas de la norme 2 s’y ramène en considérant la fonction f 2.Il apparaît aussitôt que si f est petite pour N size=1秊, elle est aussi petite pour 1 et 2 (si l’intervalle I n’est pas trop grand, cela va sans dire...), mais f peut fort bien être petite pour 1 sans l’être pour N size=1秊 (phénomène de «pointe», fig. 2). Mathématiquement, ces considérations peuvent être précisées par les inégalités: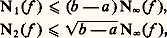 qui expriment l’inégalité de la moyenne. De même, l’inégalité de Schwarz montre aussitôt que:
qui expriment l’inégalité de la moyenne. De même, l’inégalité de Schwarz montre aussitôt que: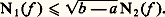 Ainsi, sur un intervalle compact, la convergence uniforme implique la convergence en moyenne quadratique, laquelle implique la convergence en moyenne. Mais les réciproques sont fausses, ce qui signifie que ces normes ne sont pas équivalentes.Les trois exemples fondamentaux précédents se généralisent au cas où il est utile d’introduire un poids , c’est-à-dire une fonction 神 continue sur [a , b ] à valeurs réelles strictement positives. On pose alors N size=1神 size=1秊(f ) = N size=1秊( 神f ) et des définitions analogues pour les autres normes.Ces exemples se généralisent aussitôt au cas des fonctions continues sur une partie compacte de Rn ou au cas des fonctions continues à support compact.Dans la plupart des questions de convergence, il est indispensable que les espaces normés considérés soient complets (espaces de Banach ). C’est le cas de l’espace E = 暈([a , b ]) muni de la norme N size=1秊. En revanche, ce même espace, muni de la norme 1 ou de la norme 2, n’est pas complet. La théorie de l’intégrale de Lebesgue permet de plonger respectivement E dans les espaces complets L1([a , b ]) et L2([a , b ]) des classes de fonctions intégrables ou de carré intégrable; ces espaces sont les complétés de E pour les normes 1 et 2 (cf. espaces MÉTRIQUES, INTÉGRATION ET MESURE).Les normes du type 2 sont spécialement intéressantes pour deux raisons. La première est d’ordre mathématique: elles dérivent du produit hermitien:
Ainsi, sur un intervalle compact, la convergence uniforme implique la convergence en moyenne quadratique, laquelle implique la convergence en moyenne. Mais les réciproques sont fausses, ce qui signifie que ces normes ne sont pas équivalentes.Les trois exemples fondamentaux précédents se généralisent au cas où il est utile d’introduire un poids , c’est-à-dire une fonction 神 continue sur [a , b ] à valeurs réelles strictement positives. On pose alors N size=1神 size=1秊(f ) = N size=1秊( 神f ) et des définitions analogues pour les autres normes.Ces exemples se généralisent aussitôt au cas des fonctions continues sur une partie compacte de Rn ou au cas des fonctions continues à support compact.Dans la plupart des questions de convergence, il est indispensable que les espaces normés considérés soient complets (espaces de Banach ). C’est le cas de l’espace E = 暈([a , b ]) muni de la norme N size=1秊. En revanche, ce même espace, muni de la norme 1 ou de la norme 2, n’est pas complet. La théorie de l’intégrale de Lebesgue permet de plonger respectivement E dans les espaces complets L1([a , b ]) et L2([a , b ]) des classes de fonctions intégrables ou de carré intégrable; ces espaces sont les complétés de E pour les normes 1 et 2 (cf. espaces MÉTRIQUES, INTÉGRATION ET MESURE).Les normes du type 2 sont spécialement intéressantes pour deux raisons. La première est d’ordre mathématique: elles dérivent du produit hermitien: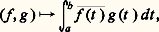 et on dispose donc de toutes les techniques hilbertiennes, très efficaces (cf. espace de HILBERT). L’autre tient au fait que ces normes se rencontrent dans de nombreux domaines de la physique mathématique: intégrales d’énergie, mécanique quantique, optimisation par la méthode des moindres carrés, processus stochastiques.En revanche, l’étude directe des normes N size=1秊 est beaucoup plus délicate (cf. infra , chap. 7 et 8).Normes et dérivationLorsqu’on s’intéresse à l’espace vectoriel Cp ([a , b ]) des fonctions de classe Cp , il convient souvent d’introduire des normes faisant intervenir les dérivés successives de f , par exemple:
et on dispose donc de toutes les techniques hilbertiennes, très efficaces (cf. espace de HILBERT). L’autre tient au fait que ces normes se rencontrent dans de nombreux domaines de la physique mathématique: intégrales d’énergie, mécanique quantique, optimisation par la méthode des moindres carrés, processus stochastiques.En revanche, l’étude directe des normes N size=1秊 est beaucoup plus délicate (cf. infra , chap. 7 et 8).Normes et dérivationLorsqu’on s’intéresse à l’espace vectoriel Cp ([a , b ]) des fonctions de classe Cp , il convient souvent d’introduire des normes faisant intervenir les dérivés successives de f , par exemple: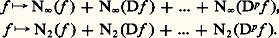 Il est indispensable d’introduire les normes sur les dérivés successives, car la convergence uniforme de (f n ) vers 0 n’entraîne pas celle des dérivées: c’est le cas par exemple pour f n (t ) = (1/n ) cos nt (il s’agit d’un phénomène d’oscillation rapide, fig. 3). En revanche, ce phénomène ne se produit pas pour les fonctions de variable complexe (cf. théorème de Weierstrass, in FONCTIONS ANALYTIQUES – Fonctions analytiques d’une variable complexe, chap. 5).Ici encore, le cas des normes 2 est plus simple à étudier. En outre, dans bon nombre de questions, on peut utiliser ces normes pour étudier les normes N size=1秊 grâce au résultat suivant: il existe des constantes 見 et 廓 telles que:
Il est indispensable d’introduire les normes sur les dérivés successives, car la convergence uniforme de (f n ) vers 0 n’entraîne pas celle des dérivées: c’est le cas par exemple pour f n (t ) = (1/n ) cos nt (il s’agit d’un phénomène d’oscillation rapide, fig. 3). En revanche, ce phénomène ne se produit pas pour les fonctions de variable complexe (cf. théorème de Weierstrass, in FONCTIONS ANALYTIQUES – Fonctions analytiques d’une variable complexe, chap. 5).Ici encore, le cas des normes 2 est plus simple à étudier. En outre, dans bon nombre de questions, on peut utiliser ces normes pour étudier les normes N size=1秊 grâce au résultat suivant: il existe des constantes 見 et 廓 telles que: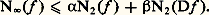 Les inégalités de ce type étendues à plusieurs variables jouent un rôle important dans la théorie des équations aux dérivées partielles; elles ont été introduites par Sobolev (cf. infra , chap. 6).Convergences définies par une famille de semi-normesLe cadre des espaces normés ne suffit pas pour couvrir les besoins de l’analyse: certains types de convergence ne peuvent être décrits à l’aide d’une norme. Voici quatre exemples importants.1. Convergence uniforme sur tout compact . Soit par exemple E l’espace vectoriel des fonctions continues sur R. La convergence uniforme sur tout compact d’une suite (f n ) vers 0 signifie que, pour tout entier p,
Les inégalités de ce type étendues à plusieurs variables jouent un rôle important dans la théorie des équations aux dérivées partielles; elles ont été introduites par Sobolev (cf. infra , chap. 6).Convergences définies par une famille de semi-normesLe cadre des espaces normés ne suffit pas pour couvrir les besoins de l’analyse: certains types de convergence ne peuvent être décrits à l’aide d’une norme. Voici quatre exemples importants.1. Convergence uniforme sur tout compact . Soit par exemple E l’espace vectoriel des fonctions continues sur R. La convergence uniforme sur tout compact d’une suite (f n ) vers 0 signifie que, pour tout entier p,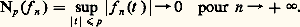 2. Convergence uniforme de toutes les dérivées d’une fonction C 秊. Par exemple, si E est l’espace des fonctions de classe C 秊 sur I = [a , b ], on dit qu’une suite (f n ) tend vers 0 en ce sens si, pour tout entier p ,
2. Convergence uniforme de toutes les dérivées d’une fonction C 秊. Par exemple, si E est l’espace des fonctions de classe C 秊 sur I = [a , b ], on dit qu’une suite (f n ) tend vers 0 en ce sens si, pour tout entier p ,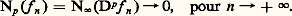 3. Fonctions de classe C 秊 à décroissance rapide ainsi que toutes leurs dérivées . Ici on considère l’espace 崙 des fonctions C 秊 sur R telles que, pour tout couple (s , k ) d’entiers naturels:
3. Fonctions de classe C 秊 à décroissance rapide ainsi que toutes leurs dérivées . Ici on considère l’espace 崙 des fonctions C 秊 sur R telles que, pour tout couple (s , k ) d’entiers naturels: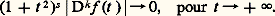 On introduit la famille dénombrable de semi-normes:
On introduit la famille dénombrable de semi-normes: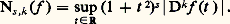 La convergence dans 崙 d’une suite (f n ) vers 0 signifie que, pour tout couple (s , k ), Ns ,k (f n )0.Cet espace joue un rôle fondamental dans la théorie de la transformation de Fourier, dans le cadre des distributions tempérées (cf. DISTRIBUTIONS, chap. 4).Ces trois exemples se généralisent aux espaces Rn .Dans ce type de situation, où intervient une famille dénombrable de semi-normes, que l’on peut ranger en une suite Np , on peut décrire la convergence au moyen d’une distance invariante par translation :
La convergence dans 崙 d’une suite (f n ) vers 0 signifie que, pour tout couple (s , k ), Ns ,k (f n )0.Cet espace joue un rôle fondamental dans la théorie de la transformation de Fourier, dans le cadre des distributions tempérées (cf. DISTRIBUTIONS, chap. 4).Ces trois exemples se généralisent aux espaces Rn .Dans ce type de situation, où intervient une famille dénombrable de semi-normes, que l’on peut ranger en une suite Np , on peut décrire la convergence au moyen d’une distance invariante par translation :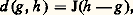 où:
où: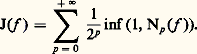 Les espaces métriques ainsi obtenus sont complets (cf. espaces MÉTRIQUES). Ce cas se distingue de celui des espaces normés par la perte de l’homogénéité .4. Convergence simple . Soit par exemple E l’espace vectoriel des fonctions définies sur R à valeurs complexes. On dit qu’une suite (f n ) converge simplement vers 0 sur R si, pour tout point x de R, la suite numérique (f n (x )) converge vers 0. On introduit les semi-normes (c’est-à-dire qu’un élément non nul peut avoir une semi-norme nulle):
Les espaces métriques ainsi obtenus sont complets (cf. espaces MÉTRIQUES). Ce cas se distingue de celui des espaces normés par la perte de l’homogénéité .4. Convergence simple . Soit par exemple E l’espace vectoriel des fonctions définies sur R à valeurs complexes. On dit qu’une suite (f n ) converge simplement vers 0 sur R si, pour tout point x de R, la suite numérique (f n (x )) converge vers 0. On introduit les semi-normes (c’est-à-dire qu’un élément non nul peut avoir une semi-norme nulle):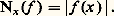 Cette fois le cadre des espaces métriques ne suffit plus pour décrire ce type de convergence, car la famille (Nx ) n’est plus dénombrable. D’ailleurs, contrairement aux apparences et à la terminologie (!), ce mode de convergence est assez pathologique car les propriétés stables sont peu nombreuses.Les quatre exemples précédents relèvent de la théorie des limites projectives d’espaces semi-normés, qui se place dans le cadre général de la théorie des espaces vectoriels topologiques localement convexes (cf. espaces vectoriels TOPOLOGIQUES, chap. 1). Dans les trois premiers exemples, les familles d’espaces normés sont dénombrables et on obtient donc des espaces de Fréchet , ce qui n’est pas le cas de l’exemple 4.Comparaison des convergences simple et uniformeIl y a deux cas importants où la convergence simple implique en fait la convergence uniforme sur tout compact.1. Cas équilipschitzien (théorème d’Ascoli classique). Soit A un espace métrique compact et (f n ) une suite d’applications de A dans C. On suppose:
Cette fois le cadre des espaces métriques ne suffit plus pour décrire ce type de convergence, car la famille (Nx ) n’est plus dénombrable. D’ailleurs, contrairement aux apparences et à la terminologie (!), ce mode de convergence est assez pathologique car les propriétés stables sont peu nombreuses.Les quatre exemples précédents relèvent de la théorie des limites projectives d’espaces semi-normés, qui se place dans le cadre général de la théorie des espaces vectoriels topologiques localement convexes (cf. espaces vectoriels TOPOLOGIQUES, chap. 1). Dans les trois premiers exemples, les familles d’espaces normés sont dénombrables et on obtient donc des espaces de Fréchet , ce qui n’est pas le cas de l’exemple 4.Comparaison des convergences simple et uniformeIl y a deux cas importants où la convergence simple implique en fait la convergence uniforme sur tout compact.1. Cas équilipschitzien (théorème d’Ascoli classique). Soit A un espace métrique compact et (f n ) une suite d’applications de A dans C. On suppose: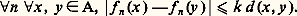 2. Cas des suites monotones (théorème de Dini). Soit encore A métrique compact et f n : AR+. On suppose:c ) la suite (f n ) converge simplement vers 0.Alors la convergence est uniforme sur A.Convergences avec conditions sur les supportsLes convergences avec conditions sur les supports jouent un rôle important dans les problèmes liés au calcul intégral et à ses extensions (mesures de Radon et distributions).Pour les mesures , considérons par exemple l’espace vectoriel E = 留(R) des fonctions à valeurs complexes continues sur R et à support compact. On est amené à considérer les suites (f n ) d’éléments de E convergeant vers 0 au sens suivant:a ) f n converge vers 0 uniformément sur R;b ) il existe un intervalle compact K = [a , b ] tel que, pour tout n , le support de f n est contenu dans K.On introduit donc les espaces vectoriels 留p (R) constitués des fonctions f dont le support est contenu dans [ 漣 p , p ], muni de la norme :
2. Cas des suites monotones (théorème de Dini). Soit encore A métrique compact et f n : AR+. On suppose:c ) la suite (f n ) converge simplement vers 0.Alors la convergence est uniforme sur A.Convergences avec conditions sur les supportsLes convergences avec conditions sur les supports jouent un rôle important dans les problèmes liés au calcul intégral et à ses extensions (mesures de Radon et distributions).Pour les mesures , considérons par exemple l’espace vectoriel E = 留(R) des fonctions à valeurs complexes continues sur R et à support compact. On est amené à considérer les suites (f n ) d’éléments de E convergeant vers 0 au sens suivant:a ) f n converge vers 0 uniformément sur R;b ) il existe un intervalle compact K = [a , b ] tel que, pour tout n , le support de f n est contenu dans K.On introduit donc les espaces vectoriels 留p (R) constitués des fonctions f dont le support est contenu dans [ 漣 p , p ], muni de la norme :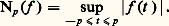 La convergence d’une suite (f n ) vers 0 signifie alors que les f n appartiennent à un même espace 留p et convergent vers 0 dans cet espace.Pour la théorie des distributions , il convient de remplacer 留(R) par l’espace 阮(R) des fonctions C 秊 sur R à support compact, et la condition (a ) par la condition:a ) pour tout entier k , la suite Dk f n converge vers 0 uniformément sur R (cf. supra , exemple 2).On introduit les espaces 阮p (R) munis de la distance introduite ci-dessus dans l’exemple 2. La convergence d’une suite f n vers 0 signifie alors que les f n appartiennent à un même espace 阮p et convergent vers 0 dans cet espace.Les espaces vectoriels 留(R) et 阮(R) sont complets (ce qui signifie ici que chacun des espaces 留p (R) ou 阮p (R) est complet).Ces deux exemples se généralisent facilement au cas des fonctions définies sur un ouvert U de Rn , en remplaçant les intervalles [ 漣 p , p ] par une suite de compacts (Kp ) tels que Kp soit contenu dans l’intérieur de Kp+1 et que U soit la réunion des Kp (suite exhaustive de compacts de U).Ils relèvent de la théorie des limites inductives d’espaces semi-normés, qu’il n’est ni commode ni naturel de placer dans le cadre de la théorie des espaces vectoriels topologiques mais qu’il convient plutôt de décrire grâce au concept d’espace vectoriel bornologique de type convexe (cf. espaces vectoriels TOPOLOGIQUES, chap. 3).2. Représentations par des intégralesForme intégrale des restesDans les problèmes de calcul différentiel, la forme intégrale des restes de développements en séries ou de développements asymptotiques est essentielle pour le contrôle de ces restes: formule de Taylor classique, formule interpolatoire de Lagrange-Hermite (cf. infra , chap. 4). À la formule de Taylor se rattache le théorème de division des fonctions différentiables : Soit f une fonction de classe Cp sur un intervalle I de centre a avec f (a ) = 0; alors f peut s’écrire sous la forme:
La convergence d’une suite (f n ) vers 0 signifie alors que les f n appartiennent à un même espace 留p et convergent vers 0 dans cet espace.Pour la théorie des distributions , il convient de remplacer 留(R) par l’espace 阮(R) des fonctions C 秊 sur R à support compact, et la condition (a ) par la condition:a ) pour tout entier k , la suite Dk f n converge vers 0 uniformément sur R (cf. supra , exemple 2).On introduit les espaces 阮p (R) munis de la distance introduite ci-dessus dans l’exemple 2. La convergence d’une suite f n vers 0 signifie alors que les f n appartiennent à un même espace 阮p et convergent vers 0 dans cet espace.Les espaces vectoriels 留(R) et 阮(R) sont complets (ce qui signifie ici que chacun des espaces 留p (R) ou 阮p (R) est complet).Ces deux exemples se généralisent facilement au cas des fonctions définies sur un ouvert U de Rn , en remplaçant les intervalles [ 漣 p , p ] par une suite de compacts (Kp ) tels que Kp soit contenu dans l’intérieur de Kp+1 et que U soit la réunion des Kp (suite exhaustive de compacts de U).Ils relèvent de la théorie des limites inductives d’espaces semi-normés, qu’il n’est ni commode ni naturel de placer dans le cadre de la théorie des espaces vectoriels topologiques mais qu’il convient plutôt de décrire grâce au concept d’espace vectoriel bornologique de type convexe (cf. espaces vectoriels TOPOLOGIQUES, chap. 3).2. Représentations par des intégralesForme intégrale des restesDans les problèmes de calcul différentiel, la forme intégrale des restes de développements en séries ou de développements asymptotiques est essentielle pour le contrôle de ces restes: formule de Taylor classique, formule interpolatoire de Lagrange-Hermite (cf. infra , chap. 4). À la formule de Taylor se rattache le théorème de division des fonctions différentiables : Soit f une fonction de classe Cp sur un intervalle I de centre a avec f (a ) = 0; alors f peut s’écrire sous la forme: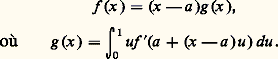 Il en découle que g est de classe Cp-1 et que, pour I compact, on a, pour tout entier k 諒 p 漣 1, la majoration:
Il en découle que g est de classe Cp-1 et que, pour I compact, on a, pour tout entier k 諒 p 漣 1, la majoration: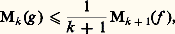 Ce théorème se généralise aussitôt à plusieurs variables: Si f (a ) = 0, avec a = (a 1, ..., a n ), alors, pour tout x = (x 1, ..., x n ), on a:
Ce théorème se généralise aussitôt à plusieurs variables: Si f (a ) = 0, avec a = (a 1, ..., a n ), alors, pour tout x = (x 1, ..., x n ), on a: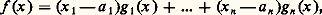 où les fonctions g i sont de classe Cp-1 si f est de classe Cp . Ce théorème est à la base de la théorie des idéaux de fonctions différentiables (cf. CALCUL INFINITÉSIMAL – Calcul à plusieurs variables, chap. 3).Transformations de Fourier et de LaplaceDans les problèmes d’analyse harmonique des phénomènes non périodiques (cf. analyse HARMONIQUE, chap. 3), on utilise la transformation de Fourier, réelle ou complexe, définie par la relation:
où les fonctions g i sont de classe Cp-1 si f est de classe Cp . Ce théorème est à la base de la théorie des idéaux de fonctions différentiables (cf. CALCUL INFINITÉSIMAL – Calcul à plusieurs variables, chap. 3).Transformations de Fourier et de LaplaceDans les problèmes d’analyse harmonique des phénomènes non périodiques (cf. analyse HARMONIQUE, chap. 3), on utilise la transformation de Fourier, réelle ou complexe, définie par la relation: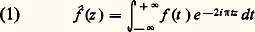 (ou des formes analogues selon les auteurs), et la formule d’inversion:
(ou des formes analogues selon les auteurs), et la formule d’inversion: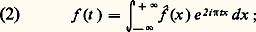 intuitivement, la formule (1) décompose le signal t 料 f (t ) suivant toutes ses composantes harmoniques (analyse harmonique du signal), tandis que la formule (2) permet de reconstituer ce signal f à partir de ses composantes (synthèse harmonique du signal).Dans le cas des fonctions définies dans [0, + 秊[, qui interviennent dans l’étude des régimes non permanents, on utilise la transformation de Laplace:
intuitivement, la formule (1) décompose le signal t 料 f (t ) suivant toutes ses composantes harmoniques (analyse harmonique du signal), tandis que la formule (2) permet de reconstituer ce signal f à partir de ses composantes (synthèse harmonique du signal).Dans le cas des fonctions définies dans [0, + 秊[, qui interviennent dans l’étude des régimes non permanents, on utilise la transformation de Laplace: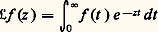 (cf. calcul SYMBOLIQUE). Cette transformation intervient aussi dans la résolution des équations différentielles à coefficients algébriques, notamment l’équation hypergéométrique (cf. calculs ASYMPTOTIQUES, chap. 6).Les transformations de Fourier et de Laplace se généralisent aussi aux espaces Rn et jouent alors un rôle fondamental dans la théorie des équations aux dérivées partielles linéaires (cf. équations aux DÉRIVÉES PARTIELLES - Théorie linéaire) et plus généralement des équations de convolution (cf. AUTOMATIQUE, théorie du SIGNAL). Elles jouent aussi un rôle de premier plan en calcul des probabilités, sous la forme des fonctions caractéristiques d’une loi de probabilité (cf. calcul des PROBABILITÉS, chap. 3), dans la théorie des processus stochastiques du second ordre (cf. processus STOCHASTIQUES, chap. 5; théorie du SIGNAL) et en mécanique quantique.On peut aussi rattacher à l’analyse harmonique la transformation de Mellin, définie par la relation:
(cf. calcul SYMBOLIQUE). Cette transformation intervient aussi dans la résolution des équations différentielles à coefficients algébriques, notamment l’équation hypergéométrique (cf. calculs ASYMPTOTIQUES, chap. 6).Les transformations de Fourier et de Laplace se généralisent aussi aux espaces Rn et jouent alors un rôle fondamental dans la théorie des équations aux dérivées partielles linéaires (cf. équations aux DÉRIVÉES PARTIELLES - Théorie linéaire) et plus généralement des équations de convolution (cf. AUTOMATIQUE, théorie du SIGNAL). Elles jouent aussi un rôle de premier plan en calcul des probabilités, sous la forme des fonctions caractéristiques d’une loi de probabilité (cf. calcul des PROBABILITÉS, chap. 3), dans la théorie des processus stochastiques du second ordre (cf. processus STOCHASTIQUES, chap. 5; théorie du SIGNAL) et en mécanique quantique.On peut aussi rattacher à l’analyse harmonique la transformation de Mellin, définie par la relation: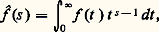 qui n’est autre que la transformation de Fourier sur le groupe multiplicatif R+ dont la mesure invariante est dt/t (cf. analyse HARMONIQUE). Cette transformation intervient notamment dans les problèmes multiplicatifs de la théorie des nombres (cf. théorie des NOMBRES-Théorie analytique); la fonction gamma d’Euler (cf. fonction GAMMA) joue ici un rôle central.Emploi de la dualitéLa dualité consiste à représenter une fonction comme une forme linéaire sur un espace E de fonctions convenablement choisi. Ainsi, toute fonction f de puissance p -ième intégrable définit une forme linéaire continue Tf sur l’espace Lq des fonctions de puissance q -ième intégrable, pour 1/p + 1/q = 1, par la formule:
qui n’est autre que la transformation de Fourier sur le groupe multiplicatif R+ dont la mesure invariante est dt/t (cf. analyse HARMONIQUE). Cette transformation intervient notamment dans les problèmes multiplicatifs de la théorie des nombres (cf. théorie des NOMBRES-Théorie analytique); la fonction gamma d’Euler (cf. fonction GAMMA) joue ici un rôle central.Emploi de la dualitéLa dualité consiste à représenter une fonction comme une forme linéaire sur un espace E de fonctions convenablement choisi. Ainsi, toute fonction f de puissance p -ième intégrable définit une forme linéaire continue Tf sur l’espace Lq des fonctions de puissance q -ième intégrable, pour 1/p + 1/q = 1, par la formule: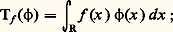 lorsque 1 麗 p 麗 + 秊, on obtient ainsi toutes les formes linéaires continues sur Lq (cf. INTÉGRATION ET MESURE, chap. 4). Mais, en utilisant d’autres espaces fonctionnels, on obtient ainsi des objets plus généraux que les fonctions. Cela tient au fait que, dans de nombreux problèmes, les opérations de passage à la limite nécessitent de sortir du cadre de la théorie des fonctions. Considérons par exemple une suite ( 﨏n ) de fonctions continues positives sur R telles que, pour tout n ,
lorsque 1 麗 p 麗 + 秊, on obtient ainsi toutes les formes linéaires continues sur Lq (cf. INTÉGRATION ET MESURE, chap. 4). Mais, en utilisant d’autres espaces fonctionnels, on obtient ainsi des objets plus généraux que les fonctions. Cela tient au fait que, dans de nombreux problèmes, les opérations de passage à la limite nécessitent de sortir du cadre de la théorie des fonctions. Considérons par exemple une suite ( 﨏n ) de fonctions continues positives sur R telles que, pour tout n ,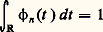 (cf. DISTRIBUTIONS, fig. 1), et dont la masse se concentre à l’origine, c’est-à-dire que, pour tout a 礪 0,
(cf. DISTRIBUTIONS, fig. 1), et dont la masse se concentre à l’origine, c’est-à-dire que, pour tout a 礪 0,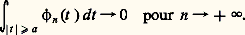 Intuitivement, les fonctions 﨏n tendent vers la «fonction» 嗀 de Dirac, que les physiciens définissent par 嗀(0) = + 秊, 嗀(x ) = 0 pour x 0 et 咽 嗀(t ) dt = 1. Mais il n’existe aucune fonction, au sens précis de ce concept en mathématiques, satisfaisant à ces relations. Il suffit de considérer, pour s’en convaincre, 2 嗀. On tourne alors la difficulté de la manière suivante: on démontre d’abord que, pour toute fonction f continue à support compact sur R,
Intuitivement, les fonctions 﨏n tendent vers la «fonction» 嗀 de Dirac, que les physiciens définissent par 嗀(0) = + 秊, 嗀(x ) = 0 pour x 0 et 咽 嗀(t ) dt = 1. Mais il n’existe aucune fonction, au sens précis de ce concept en mathématiques, satisfaisant à ces relations. Il suffit de considérer, pour s’en convaincre, 2 嗀. On tourne alors la difficulté de la manière suivante: on démontre d’abord que, pour toute fonction f continue à support compact sur R,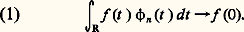 À toute fonction 﨏 continue sur R, on associe la forme linéaire:
À toute fonction 﨏 continue sur R, on associe la forme linéaire: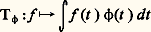 sur l’espace vectoriel E = 留(R) des fonctions continues à support compact. La relation (1) s’interprète alors de la manière suivante:
sur l’espace vectoriel E = 留(R) des fonctions continues à support compact. La relation (1) s’interprète alors de la manière suivante: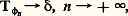 où 嗀 est la forme linéaire sur E telle que f 料 f (0). En outre, l’application 﨏 料 T size=1﨏 permet de plonger l’espace 留(R) dans son dual topologique, à savoir, l’espace 紐(R) des mesures de Radon sur R [cf. INTÉGRATION ET MESURE]. Lorsque E est l’espace 阮(R), on obtient les distributions [cf. DISTRIBUTIONS (mathématiques)].Le principal intérêt de ces généralisations de la notion de fonction est de fournir un cadre théorique permettant d’opérer en toute sécurité sur les représentations (cf. infra , chap. 5). L’utilisation des transformations de Fourier et de Laplace pour le calcul symbolique et les équations aux dérivées partielles est à cet égard exemplaire.Noyaux de convolutionLes noyaux de convolution constituent un autre exemple très intéressant de représentation intégrale. Ils interviennent d’abord dans la résolution des équations différentielles à coefficients constants avec second membre P(D)f = b , f (0) = 0; si on introduit la solution élémentaire E définie par la relation P(D)E = 嗀, où 嗀 est la mesure de Dirac, alors f = E b , c’est-à-dire:
où 嗀 est la forme linéaire sur E telle que f 料 f (0). En outre, l’application 﨏 料 T size=1﨏 permet de plonger l’espace 留(R) dans son dual topologique, à savoir, l’espace 紐(R) des mesures de Radon sur R [cf. INTÉGRATION ET MESURE]. Lorsque E est l’espace 阮(R), on obtient les distributions [cf. DISTRIBUTIONS (mathématiques)].Le principal intérêt de ces généralisations de la notion de fonction est de fournir un cadre théorique permettant d’opérer en toute sécurité sur les représentations (cf. infra , chap. 5). L’utilisation des transformations de Fourier et de Laplace pour le calcul symbolique et les équations aux dérivées partielles est à cet égard exemplaire.Noyaux de convolutionLes noyaux de convolution constituent un autre exemple très intéressant de représentation intégrale. Ils interviennent d’abord dans la résolution des équations différentielles à coefficients constants avec second membre P(D)f = b , f (0) = 0; si on introduit la solution élémentaire E définie par la relation P(D)E = 嗀, où 嗀 est la mesure de Dirac, alors f = E b , c’est-à-dire: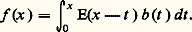 Cette méthode s’applique aussi aux équations aux dérivées partielles à coefficients constants (cf. équations aux DÉRIVÉES PARTIELLES-Théorie linéaire). En particulier, dans le cas du laplacien en dimension trois, on a:
Cette méthode s’applique aussi aux équations aux dérivées partielles à coefficients constants (cf. équations aux DÉRIVÉES PARTIELLES-Théorie linéaire). En particulier, dans le cas du laplacien en dimension trois, on a: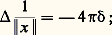 la solution élémentaire est donc E(x ) = 漣 1/4 神 瑩x 瑩. Le potentiel V, solution de l’équation de Poisson V = 漣 4 神猪, où 猪 est à support compact, est donc donné par l’intégrale de convolution:
la solution élémentaire est donc E(x ) = 漣 1/4 神 瑩x 瑩. Le potentiel V, solution de l’équation de Poisson V = 漣 4 神猪, où 猪 est à support compact, est donc donné par l’intégrale de convolution: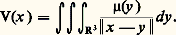 De même, la résolution du problème de Dirichlet pour le cercle fait intervenir le noyau de Poisson (cf. POTENTIEL ET FONCTIONS HARMONIQUES, chap. 1).L’importance des noyaux de convolution s’explique par le fait qu’ils peuvent décrire tous les problèmes linéaires invariants par translation de la variable. Plus précisément, soit f une fonction continue; alors, l’application u f qui, à tout élément 﨏 de 阮, associe f 﨏 est une application linéaire continue de 阮 dans l’espace 劉 des fonctions indéfiniment dérivables. En outre, elle est invariante par translation sur la variable, c’est-à-dire qu’elle commute à tous les opérateurs de translation Ta définis par Ta 﨏(x ) = 﨏(x 漣 a ).Le problème central est alors de savoir si, inversement, toute application linéaire continue invariante par translation est de la forme précédente. La réponse est négative dans le cadre de la théorie des fonctions (penser par exemple à l’application identique), mais elle est positive dans le cadre de la théorie des distributions: si u : face=F0021 阮阮 , linéaire continue, commute aux translations, alors il existe une distribution T et une seule telle que u ( 﨏) = 﨏. En outre, u se prolonge en une application linéaire continue u de 劉 dans 阮 et, dans ces conditions, T = u ( 嗀). Dans tous les théorèmes de théorie du signal et d’automatique, ce résultat joue un rôle fondamental; T s’appelle la «fonction» de transfert ou réponse impulsionnelle (cf. calcul SYMBOLIQUE, AUTOMATIQUE).Intégrales de contourLa formule intégrale de Cauchy, fondamentale dans la théorie des fonctions de variable complexe (cf. FONCTIONS ANALYTIQUES – Fonctions analytiques d’une variable, chap. 5), s’interprète aussi dans ce cadre; on utilise cette fois la solution élémentaire de l’opérateur 煉/ 煉 磻 :
De même, la résolution du problème de Dirichlet pour le cercle fait intervenir le noyau de Poisson (cf. POTENTIEL ET FONCTIONS HARMONIQUES, chap. 1).L’importance des noyaux de convolution s’explique par le fait qu’ils peuvent décrire tous les problèmes linéaires invariants par translation de la variable. Plus précisément, soit f une fonction continue; alors, l’application u f qui, à tout élément 﨏 de 阮, associe f 﨏 est une application linéaire continue de 阮 dans l’espace 劉 des fonctions indéfiniment dérivables. En outre, elle est invariante par translation sur la variable, c’est-à-dire qu’elle commute à tous les opérateurs de translation Ta définis par Ta 﨏(x ) = 﨏(x 漣 a ).Le problème central est alors de savoir si, inversement, toute application linéaire continue invariante par translation est de la forme précédente. La réponse est négative dans le cadre de la théorie des fonctions (penser par exemple à l’application identique), mais elle est positive dans le cadre de la théorie des distributions: si u : face=F0021 阮阮 , linéaire continue, commute aux translations, alors il existe une distribution T et une seule telle que u ( 﨏) = 﨏. En outre, u se prolonge en une application linéaire continue u de 劉 dans 阮 et, dans ces conditions, T = u ( 嗀). Dans tous les théorèmes de théorie du signal et d’automatique, ce résultat joue un rôle fondamental; T s’appelle la «fonction» de transfert ou réponse impulsionnelle (cf. calcul SYMBOLIQUE, AUTOMATIQUE).Intégrales de contourLa formule intégrale de Cauchy, fondamentale dans la théorie des fonctions de variable complexe (cf. FONCTIONS ANALYTIQUES – Fonctions analytiques d’une variable, chap. 5), s’interprète aussi dans ce cadre; on utilise cette fois la solution élémentaire de l’opérateur 煉/ 煉 磻 :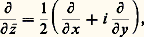 à savoir:
à savoir: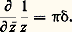 La méthode se généralise aux fonctions analytiques de plusieurs variables (cf. FONCTIONS ANALYTIQUES -Fonctions analytiques de plusieurs variables).La formule intégrale de Cauchy conduit à étudier plus généralement la transformation de Hilbert:
La méthode se généralise aux fonctions analytiques de plusieurs variables (cf. FONCTIONS ANALYTIQUES -Fonctions analytiques de plusieurs variables).La formule intégrale de Cauchy conduit à étudier plus généralement la transformation de Hilbert: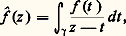 où f est une fonction continue définie sur un arc 塚 du plan complexe. Cette transformation intervient dans le problème des moments.Elle conduit aussi à la recherche de représentations des fonctions holomorphes et méromorphes par des intégrales de contour. Le cas des fonctions hypergéométriques en est un exemple significatif (cf. calculs ASYMPTOTIQUES chap. 6).Noyaux intégrauxLa représentation des fonctions par des noyaux intégraux s’applique aussi à l’étude des phénomènes linéaires non nécessairement invariants par translation. C’est le cas pour la résolution des équations linéaires à coefficients non constants.On introduit à cet effet la résolvante de l’équation sans second membre:
où f est une fonction continue définie sur un arc 塚 du plan complexe. Cette transformation intervient dans le problème des moments.Elle conduit aussi à la recherche de représentations des fonctions holomorphes et méromorphes par des intégrales de contour. Le cas des fonctions hypergéométriques en est un exemple significatif (cf. calculs ASYMPTOTIQUES chap. 6).Noyaux intégrauxLa représentation des fonctions par des noyaux intégraux s’applique aussi à l’étude des phénomènes linéaires non nécessairement invariants par translation. C’est le cas pour la résolution des équations linéaires à coefficients non constants.On introduit à cet effet la résolvante de l’équation sans second membre: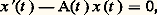 où, pour tout t , A(t ) est une matrice carrée d’ordre n à coefficients complexes et x (t ) un élément de Cn : c’est la fonction R(s , t ), à valeurs vectorielles, solution du problème de Cauchy:
où, pour tout t , A(t ) est une matrice carrée d’ordre n à coefficients complexes et x (t ) un élément de Cn : c’est la fonction R(s , t ), à valeurs vectorielles, solution du problème de Cauchy: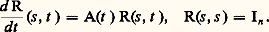 Dans ces conditions, l’unique solution du problème de Cauchy:
Dans ces conditions, l’unique solution du problème de Cauchy: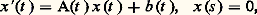 est donnée par:
est donnée par: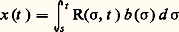 (cf. équations DIFFÉRENTIELLES). Placée dans le cadre de la théorie des distributions, cette méthode s’étend aux équations aux dérivées partielles linéaires grâce au concept de noyau élémentaire (cf. équations aux DÉRIVÉES PARTIELLES - Théorie linéaire).Les noyaux intégraux interviennent aussi dans la théorie des fonctions de Green (cf. équations DIFFÉRENTIELLES, chap. 3; POTENTIEL ET FONCTIONS HARMONIQUES), dans la résolution des équations intégrales (cf. équations INTÉGRALES) et, plus généralement, dans la théorie des opérateurs. Par exemple, si K est une fonction de carré intégrable sur R2, alors, pour toute f 捻 L2(R), la fonction g définie presque partout par la relation:
(cf. équations DIFFÉRENTIELLES). Placée dans le cadre de la théorie des distributions, cette méthode s’étend aux équations aux dérivées partielles linéaires grâce au concept de noyau élémentaire (cf. équations aux DÉRIVÉES PARTIELLES - Théorie linéaire).Les noyaux intégraux interviennent aussi dans la théorie des fonctions de Green (cf. équations DIFFÉRENTIELLES, chap. 3; POTENTIEL ET FONCTIONS HARMONIQUES), dans la résolution des équations intégrales (cf. équations INTÉGRALES) et, plus généralement, dans la théorie des opérateurs. Par exemple, si K est une fonction de carré intégrable sur R2, alors, pour toute f 捻 L2(R), la fonction g définie presque partout par la relation: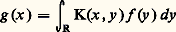 appartient encore à L2(R) et l’application f 料 g est un endomorphisme continu de l’espace de Hilbert L2. Mais, inversement, tout endomorphisme continu de L2 n’est pas nécessairement de cette forme: on obtient ainsi seulement les opérateurs de Hilbert-Schmidt (cf. théorie SPECTRALE, chap. 2).Pour obtenir un énoncé satisfaisant, le cadre de la théorie des fonctions ne suffit pas; il convient d’utiliser la théorie des distributions. Soit K une distribution sur R2; alors, pour toute fonction 祥 捻 阮(R), l’application:
appartient encore à L2(R) et l’application f 料 g est un endomorphisme continu de l’espace de Hilbert L2. Mais, inversement, tout endomorphisme continu de L2 n’est pas nécessairement de cette forme: on obtient ainsi seulement les opérateurs de Hilbert-Schmidt (cf. théorie SPECTRALE, chap. 2).Pour obtenir un énoncé satisfaisant, le cadre de la théorie des fonctions ne suffit pas; il convient d’utiliser la théorie des distributions. Soit K une distribution sur R2; alors, pour toute fonction 祥 捻 阮(R), l’application: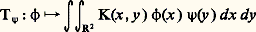 est une distribution sur R et l’application u K qui à 祥 associe T size=1祥 est une application linéaire de 阮(R) dans 阮 (R), continue en ce sens que, si 﨏n tend vers 0 dans 阮, alors T size=1﨏n tend vers 0 dans 阮 . Le célèbre théorème des noyaux de Laurent Schwartz affirme que, réciproquement, toute application linéaire continue de 阮 dans 阮 est de cette forme, c’est-à-dire peut être définie par un noyau distribution.3. Représentations par des sériesSéries entièresLa somme d’une série entière de rayon de convergence R est une fonction indéfiniment différentiable dans son disque de convergence, et les dérivées successives à l’origine sont données par la formule de Taylor.Inversement, dans de nombreux problèmes, il est utile de représenter une fonction f de classe C 秊 par sa série de Taylor. Mais ici la situation est très différente selon qu’on se place sur le corps des nombres complexes ou sur celui des nombres réels. Dans le premier cas, la série de Taylor converge toujours vers la fonction dans tout disque où f est de classe C 秊 (d’ailleurs la dérivabilité suffit; cf. FONCTIONS ANALYTIQUES - Fonctions analytiques d’une variable complexe, chap. 2). Dans le cas du corps des réels, il existe des fonctions C 秊 dans un intervalle ] 漣 a , a [ dont la série de Taylor converge, mais vers une autre fonction: c’est le cas de la fonction f définie par f (0) = 0, f (x ) = exp(face=F0019 漣 1/x 2), exemple introduit par Cauchy dans son Cours d’analyse (1821). Il existe aussi des fonctions C 秊 dont la série de Taylor a un rayon de convergence nul: c’est le cas de la fonction:
est une distribution sur R et l’application u K qui à 祥 associe T size=1祥 est une application linéaire de 阮(R) dans 阮 (R), continue en ce sens que, si 﨏n tend vers 0 dans 阮, alors T size=1﨏n tend vers 0 dans 阮 . Le célèbre théorème des noyaux de Laurent Schwartz affirme que, réciproquement, toute application linéaire continue de 阮 dans 阮 est de cette forme, c’est-à-dire peut être définie par un noyau distribution.3. Représentations par des sériesSéries entièresLa somme d’une série entière de rayon de convergence R est une fonction indéfiniment différentiable dans son disque de convergence, et les dérivées successives à l’origine sont données par la formule de Taylor.Inversement, dans de nombreux problèmes, il est utile de représenter une fonction f de classe C 秊 par sa série de Taylor. Mais ici la situation est très différente selon qu’on se place sur le corps des nombres complexes ou sur celui des nombres réels. Dans le premier cas, la série de Taylor converge toujours vers la fonction dans tout disque où f est de classe C 秊 (d’ailleurs la dérivabilité suffit; cf. FONCTIONS ANALYTIQUES - Fonctions analytiques d’une variable complexe, chap. 2). Dans le cas du corps des réels, il existe des fonctions C 秊 dans un intervalle ] 漣 a , a [ dont la série de Taylor converge, mais vers une autre fonction: c’est le cas de la fonction f définie par f (0) = 0, f (x ) = exp(face=F0019 漣 1/x 2), exemple introduit par Cauchy dans son Cours d’analyse (1821). Il existe aussi des fonctions C 秊 dont la série de Taylor a un rayon de convergence nul: c’est le cas de la fonction: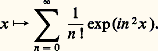 Plus précisément, Émile Borel a montré que, pour toute suite (a n ) de nombres complexes, il existe une fonction C 秊 sur R telle que, pour tout n , f (n) (0) = a n . Autrement dit, l’application de Taylor T de C 秊(R) dans l’anneau C[[X]] des séries formelles à coefficients complexes, définie par:
Plus précisément, Émile Borel a montré que, pour toute suite (a n ) de nombres complexes, il existe une fonction C 秊 sur R telle que, pour tout n , f (n) (0) = a n . Autrement dit, l’application de Taylor T de C 秊(R) dans l’anneau C[[X]] des séries formelles à coefficients complexes, définie par: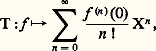 est surjective .Il n’est donc pas possible, comme l’a tenté Lagrange dans la Théorie des fonctions analytiques (1797), de fonder le calcul différentiel sur le développement en série de Taylor.Ce phénomène est à l’origine du concept de fonction analytique réelle: ce sont les fonctions de classe C 秊 dans un intervalle ouvert I de R développables en série de Taylor au voisinage de chaque point a de I. Ces fonctions peuvent être caractérisées parmi les fonctions C 秊 dans I à l’aide d’inégalités du type suivant, portant sur la rapidité de croissance des modules des dérivées successives: pour tout intervalle compact K contenu dans I, il existe des constantes CK et r K telles que l’on ait, pour tout entier n :
est surjective .Il n’est donc pas possible, comme l’a tenté Lagrange dans la Théorie des fonctions analytiques (1797), de fonder le calcul différentiel sur le développement en série de Taylor.Ce phénomène est à l’origine du concept de fonction analytique réelle: ce sont les fonctions de classe C 秊 dans un intervalle ouvert I de R développables en série de Taylor au voisinage de chaque point a de I. Ces fonctions peuvent être caractérisées parmi les fonctions C 秊 dans I à l’aide d’inégalités du type suivant, portant sur la rapidité de croissance des modules des dérivées successives: pour tout intervalle compact K contenu dans I, il existe des constantes CK et r K telles que l’on ait, pour tout entier n :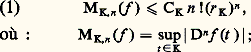 ce résultat est dû à Pringsheim.Bien entendu, en tout point a 捻 I, l’application de Taylor Ta est injective sur le sous-espace vectoriel C 諸(I) des fonctions analytiques dans I. Plus généralement, on dit qu’un sous-espace vectoriel V de C 秊(I) est quasi analytique si la restriction de Ta à V est injective.La condition (1) conduit plus généralement à considérer une suite croissante b = ( 廓n ) tendant vers + 秊 et logarithmiquement convexe, c’est-à-dire vérifiant 廓2n 諒 廓n-1 廓n+1 , et à introduire la sous-algèbre Vb de C 秊(I) constituée des fonctions f telles que l’on ait:
ce résultat est dû à Pringsheim.Bien entendu, en tout point a 捻 I, l’application de Taylor Ta est injective sur le sous-espace vectoriel C 諸(I) des fonctions analytiques dans I. Plus généralement, on dit qu’un sous-espace vectoriel V de C 秊(I) est quasi analytique si la restriction de Ta à V est injective.La condition (1) conduit plus généralement à considérer une suite croissante b = ( 廓n ) tendant vers + 秊 et logarithmiquement convexe, c’est-à-dire vérifiant 廓2n 諒 廓n-1 廓n+1 , et à introduire la sous-algèbre Vb de C 秊(I) constituée des fonctions f telles que l’on ait: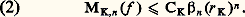 Le théorème de Denjoy-Carleman affirme que Vb est quasi analytique si et seulement si la série de terme général ( 廓n ) size=1漣1/n est divergente.Si Vb est quasi analytique, ses éléments ont des propriétés très rigides: en particulier, le principe du prolongement analytique est valable et Vb 惡 阮(I) est réduit à0. Au contraire, si Vb n’est pas quasi analytique, 阮b (I) = Vb 惡 阮(I) est dense dans 阮(I) et les propriétés de Vb ressemblent à celles de 阮(I). L’exemple le plus intéressant est fourni par les classes de Gevrey, où 廓n = (n !)s , s 礪 1, auquel cas Vb se note 阮s (I); cet espace étant muni d’un type de convergence analogue à celui de 阮(I), son dual topologique est constitué des ultradistributions: il est analogue à 阮 (I) mais beaucoup plus grand. Ces espaces interviennent dans l’étude des problèmes aux limites des équations aux dérivées partielles, où l’on introduit aussi l’espace vectoriel des fonctionnelles analytiques, c’est-à-dire le dual topologique de C 諸(I), dont les propriétés diffèrent profondément de celles des distributions (cf. équations aux DÉRIVÉES PARTIELLES - Analyse microlocale).Séries de polynômesPuisque les séries entières ne suffisent pas pour représenter des fonctions suffisamment générales (continues, de classe Ck ), il convient de considérer des séries de polynômes. D’après le théorème de Weierstrass (1886), toute fonction continue sur un intervalle compact est développable en série uniformément convergente de polynômes. Le point de vue de Newton et de Lagrange se trouve ainsi justifié, mais dans un cadre théorique plus approfondi. Weierstrass considère d’ailleurs que ce résultat constitue une définition constructive de la notion de fonction continue.Les séries de polynômes et de fractions rationnelles sont aussi utiles dans la représentation des fonctions d’une variable complexe lorsque le domaine de définition n’est plus un disque ou dans le cas où la fonction présente des singularités (cf. Développements eulériens, in EXPONENTIELLE ET LOGARITHME; Théorème de Runge, in FONCTIONS ANALYTIQUES - Fonctions analytiques d’une variable, chap. 8 et 9). Dans d’autres questions, il est commode d’utiliser des produits infinis (cf. Théorème de Runge, in FONCTIONS ANALYTIQUES - FONCTIONS ANAlytiques d’une variable, chap. 9), ou des séries de Dirichlet.Analyse algébriqueLes manipulations sur les séries entières et ces autres objets constituent le cœur de l’analyse algébrique , développée dans un cadre formel par Euler dans l’Introductio in analysin infinitorum (1748) et reprise dans le cadre du concept de convergence par Cauchy. L’analyse algébrique intervient dans la théorie des fonctions transcendantes élémentaires [cf. EXPONENTIELLE ET LOGARITHME] et, plus généralement, des fonctions spéciales (cf. fonctions de BESSEL, FONCTIONS ANALYTIQUES - Fonctions elliptiques et modulaire, fonction GAMMA); elle intervient aussi dans les problèmes arithmétiques et combinatoires grâce au concept de série génératrice: séries entières pour les problèmes additifs, séries de Dirichlet pour les problèmes multiplicatifs (cf. analyse COMBINATOIRE, théorie des NOMBRES - Théorie analytique des nombres).Séries de FourierDans les problèmes d’analyse harmonique des phénomènes périodiques (de période 1 pour fixer les idées), on utilise le développement des fonctions périodiques en série de Fourier:
Le théorème de Denjoy-Carleman affirme que Vb est quasi analytique si et seulement si la série de terme général ( 廓n ) size=1漣1/n est divergente.Si Vb est quasi analytique, ses éléments ont des propriétés très rigides: en particulier, le principe du prolongement analytique est valable et Vb 惡 阮(I) est réduit à0. Au contraire, si Vb n’est pas quasi analytique, 阮b (I) = Vb 惡 阮(I) est dense dans 阮(I) et les propriétés de Vb ressemblent à celles de 阮(I). L’exemple le plus intéressant est fourni par les classes de Gevrey, où 廓n = (n !)s , s 礪 1, auquel cas Vb se note 阮s (I); cet espace étant muni d’un type de convergence analogue à celui de 阮(I), son dual topologique est constitué des ultradistributions: il est analogue à 阮 (I) mais beaucoup plus grand. Ces espaces interviennent dans l’étude des problèmes aux limites des équations aux dérivées partielles, où l’on introduit aussi l’espace vectoriel des fonctionnelles analytiques, c’est-à-dire le dual topologique de C 諸(I), dont les propriétés diffèrent profondément de celles des distributions (cf. équations aux DÉRIVÉES PARTIELLES - Analyse microlocale).Séries de polynômesPuisque les séries entières ne suffisent pas pour représenter des fonctions suffisamment générales (continues, de classe Ck ), il convient de considérer des séries de polynômes. D’après le théorème de Weierstrass (1886), toute fonction continue sur un intervalle compact est développable en série uniformément convergente de polynômes. Le point de vue de Newton et de Lagrange se trouve ainsi justifié, mais dans un cadre théorique plus approfondi. Weierstrass considère d’ailleurs que ce résultat constitue une définition constructive de la notion de fonction continue.Les séries de polynômes et de fractions rationnelles sont aussi utiles dans la représentation des fonctions d’une variable complexe lorsque le domaine de définition n’est plus un disque ou dans le cas où la fonction présente des singularités (cf. Développements eulériens, in EXPONENTIELLE ET LOGARITHME; Théorème de Runge, in FONCTIONS ANALYTIQUES - Fonctions analytiques d’une variable, chap. 8 et 9). Dans d’autres questions, il est commode d’utiliser des produits infinis (cf. Théorème de Runge, in FONCTIONS ANALYTIQUES - FONCTIONS ANAlytiques d’une variable, chap. 9), ou des séries de Dirichlet.Analyse algébriqueLes manipulations sur les séries entières et ces autres objets constituent le cœur de l’analyse algébrique , développée dans un cadre formel par Euler dans l’Introductio in analysin infinitorum (1748) et reprise dans le cadre du concept de convergence par Cauchy. L’analyse algébrique intervient dans la théorie des fonctions transcendantes élémentaires [cf. EXPONENTIELLE ET LOGARITHME] et, plus généralement, des fonctions spéciales (cf. fonctions de BESSEL, FONCTIONS ANALYTIQUES - Fonctions elliptiques et modulaire, fonction GAMMA); elle intervient aussi dans les problèmes arithmétiques et combinatoires grâce au concept de série génératrice: séries entières pour les problèmes additifs, séries de Dirichlet pour les problèmes multiplicatifs (cf. analyse COMBINATOIRE, théorie des NOMBRES - Théorie analytique des nombres).Séries de FourierDans les problèmes d’analyse harmonique des phénomènes périodiques (de période 1 pour fixer les idées), on utilise le développement des fonctions périodiques en série de Fourier: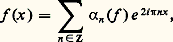 où le coefficient de Fourier 見n est donné par:
où le coefficient de Fourier 見n est donné par: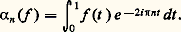 La problématique est ici la même que pour la transformation de Fourier. Les deux cadres théoriques principaux de validité de cette représentation sont l’espace des fonctions de carré intégrable sur [0, 1] et l’espace des distributions périodiques (cf. DISTRIBUTIONS, SÉRIES TRIGONOMÉTRIQUES). C’est d’ailleurs l’étude des séries de Fourier qui a constitué une des principales motivations de la construction de l’intégrale de Lebesgue et de l’espace L2.La représentation par les séries de Fourier s’insère dans un cadre plus général: pour étudier un opérateur auto-adjoint d’un espace hilbertien de fonctions, on développe les fonctions en série de fonctions propres de cet opérateur, ce qui est possible lorsqu’elles constituent une base hilbertienne; le cas des séries de Fourier est relatif à l’opérateur de dérivation. Le cas des équations différentielles conduit à la théorie de Sturm-Liouville et à l’introduction des systèmes classiques de fonctions orthogonales (cf. équations DIFFÉRENTIELLES, chap. 3; polynômes ORTHOGONAUX). L’étude des équations intégrales, en particulier des équations de Fredholm, qu’il convient de placer dans le cadre des opérateurs compacts, utilise aussi ce type de représentation (cf. équations INTÉGRALES; théorie SPECTRALE).Cette même méthode s’applique encore à l’étude de problèmes relatifs aux équations aux dérivées partielles; une idée centrale pour déterminer les fonctions propres consiste ici à se ramener au cas des équations différentielles par la méthode de séparation des variables.4. Approximation par des suitesLe problème de la représentation des fonctions comme limites de fonctions plus simples est intimement lié à celui de l’approximation des fonctions, qui ne relève pas uniquement de problèmes d’analyse numérique mais constitue un mode de représentation utile dans des questions d’ordre théorique: problèmes d’existence et d’unicité, démonstration de théorèmes par passage à la limite (argument de densité...). Les procédés d’approximations sont très divers; nous avons retenu cinq méthodes importantes.Méthodes convolutivesOn utilise l’effet régularisant de la convolution: si f est une fonction peu régulière et si 﨏 est très régulière, alors f 﨏 est aussi régulière que 﨏. En introduisant une approximation de l’unité , c’est-à-dire une suite ( 﨏n ) de fonctions très régulières convergeant vers la mesure de Dirac 嗀 (cf. supra , chap. 2), on approche f par des fonctions très régulières f 﨏n = f n .Le fait que les fonctions 﨏n soient à valeurs positives joue ici un rôle essentiel. Ce procédé d’approximation est particulièrement intéressant: en effet, lorsque f est de classe Cp , non seulement f n converge vers f , mais, pour tout k 諒 p , les dérivés Dk f n convergent vers Dk f . En prenant pour 﨏n des fonctions C 秊 à support compact, on obtient la densité des fonctions C 秊 dans la plupart des espaces fonctionnels classiques et même des espaces de distributions; ainsi, pour tout ouvert U de Rn , l’espace vectoriel 阮(U) des fonctions de classe C 秊 dans U à support compact est dense dans l’espace vectoriel 留(U) des fonctions continues à support compact contenu dans U.En prenant pour 﨏n des fonctions polynomiales, on obtient une démonstration du théorème d’approximation polynomiale de Weierstrass; on peut prendre par exemple le noyau de Landau:
La problématique est ici la même que pour la transformation de Fourier. Les deux cadres théoriques principaux de validité de cette représentation sont l’espace des fonctions de carré intégrable sur [0, 1] et l’espace des distributions périodiques (cf. DISTRIBUTIONS, SÉRIES TRIGONOMÉTRIQUES). C’est d’ailleurs l’étude des séries de Fourier qui a constitué une des principales motivations de la construction de l’intégrale de Lebesgue et de l’espace L2.La représentation par les séries de Fourier s’insère dans un cadre plus général: pour étudier un opérateur auto-adjoint d’un espace hilbertien de fonctions, on développe les fonctions en série de fonctions propres de cet opérateur, ce qui est possible lorsqu’elles constituent une base hilbertienne; le cas des séries de Fourier est relatif à l’opérateur de dérivation. Le cas des équations différentielles conduit à la théorie de Sturm-Liouville et à l’introduction des systèmes classiques de fonctions orthogonales (cf. équations DIFFÉRENTIELLES, chap. 3; polynômes ORTHOGONAUX). L’étude des équations intégrales, en particulier des équations de Fredholm, qu’il convient de placer dans le cadre des opérateurs compacts, utilise aussi ce type de représentation (cf. équations INTÉGRALES; théorie SPECTRALE).Cette même méthode s’applique encore à l’étude de problèmes relatifs aux équations aux dérivées partielles; une idée centrale pour déterminer les fonctions propres consiste ici à se ramener au cas des équations différentielles par la méthode de séparation des variables.4. Approximation par des suitesLe problème de la représentation des fonctions comme limites de fonctions plus simples est intimement lié à celui de l’approximation des fonctions, qui ne relève pas uniquement de problèmes d’analyse numérique mais constitue un mode de représentation utile dans des questions d’ordre théorique: problèmes d’existence et d’unicité, démonstration de théorèmes par passage à la limite (argument de densité...). Les procédés d’approximations sont très divers; nous avons retenu cinq méthodes importantes.Méthodes convolutivesOn utilise l’effet régularisant de la convolution: si f est une fonction peu régulière et si 﨏 est très régulière, alors f 﨏 est aussi régulière que 﨏. En introduisant une approximation de l’unité , c’est-à-dire une suite ( 﨏n ) de fonctions très régulières convergeant vers la mesure de Dirac 嗀 (cf. supra , chap. 2), on approche f par des fonctions très régulières f 﨏n = f n .Le fait que les fonctions 﨏n soient à valeurs positives joue ici un rôle essentiel. Ce procédé d’approximation est particulièrement intéressant: en effet, lorsque f est de classe Cp , non seulement f n converge vers f , mais, pour tout k 諒 p , les dérivés Dk f n convergent vers Dk f . En prenant pour 﨏n des fonctions C 秊 à support compact, on obtient la densité des fonctions C 秊 dans la plupart des espaces fonctionnels classiques et même des espaces de distributions; ainsi, pour tout ouvert U de Rn , l’espace vectoriel 阮(U) des fonctions de classe C 秊 dans U à support compact est dense dans l’espace vectoriel 留(U) des fonctions continues à support compact contenu dans U.En prenant pour 﨏n des fonctions polynomiales, on obtient une démonstration du théorème d’approximation polynomiale de Weierstrass; on peut prendre par exemple le noyau de Landau: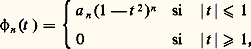 où a n est une constante de normalisation, c’est-à-dire telle que:
où a n est une constante de normalisation, c’est-à-dire telle que: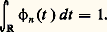 La même méthode s’applique aussi à l’approximation uniforme des fonctions continues périodiques: on peut prendre par exemple les noyaux de Fejer (cf. SÉRIES TRIGONOMÉTRIQUES, chap. 1) ou de La Vallée Poussin:
La même méthode s’applique aussi à l’approximation uniforme des fonctions continues périodiques: on peut prendre par exemple les noyaux de Fejer (cf. SÉRIES TRIGONOMÉTRIQUES, chap. 1) ou de La Vallée Poussin: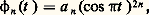 où a n est une constante de normalisation.On notera que, en revanche, le noyau de Dirichlet (cf. SÉRIES TRIGONOMÉTRIQUES, chap. 1) ne convient pas pour toutes les fonctions continues, ce qui se traduit par le fait que la série de Fourier d’une fonction continue peut diverger; cela tient au fait que ce noyau n’est pas positif. Mais la convergence a bien lieu si la fonction est suffisamment régulière, c’est-à-dire si le module de continuité (cf. infra , chap. 7) décroît assez vite.Méthodes de troncatureIl s’agit d’approcher des fonctions définies sur un ouvert U de Rn par des fonctions à support compact contenu dans U. À cet effet, on utilise une suite exhaustive (Kn ) de compacts de U (cf. supra , chap. 1) et on construit une troncature universelle , c’està-dire une suite ( 﨑n ) de fonctions telles que 0 諒 﨑n 諒 1, 﨑n = 1 sur Kn et 﨑n+1 = 0 en dehors de Kn+1 .Dans des questions d’intégration, on peut prendre pour 﨑n la fonction caractéristique de Kn . Dans d’autres problèmes, il faut opérer moins brutalement. Par exemple, en prenant 﨑n continue, on prouve que l’espace vectoriel 留(U) des fonctions continues à support compact contenu dans U est dense dans l’espace vectoriel 暈0(U) des fonctions continues tendant vers 0 au bord de U (muni de la norme de la convergence uniforme) ou encore dans l’espace L2(U) des classes de fonctions de carré intégrable dans U (muni de la norme quadratique).De même, on peut prendre 﨑n de classe C 秊; on prouve alors que l’espace vectoriel 阮(R) des fonctions de classe C 秊 à support compact est dense dans l’espace vectoriel 崙(R) des fonctions de classe C 秊 à décroissance rapide.On peut conjuguer les méthodes de convolution et de troncature pour montrer par exemple que l’espace vectoriel 阮(U) est dense dans l’espace vectoriel 暈(U) pour la convergence uniforme sur tout compact (cf. supra , chap. 1).Méthodes itérativesIl s’agit ici de méthodes où l’algorithme d’approximation de f est défini par une relation de récurrence. En voici trois exemples, dont les deux premiers sont d’importance capitale.Méthode des approximations successivesPour prouver l’existence et l’unicité et étudier les solutions d’équations portant sur des fonctions, on s’inspire du cas des équations numériques en généralisant la méthode des approximations successives [cf. CALCUL NUMÉRIQUE (HISTOIRE DU)] au cadre abstrait des espaces métriques complets (cf. espaces MÉTRIQUES, chap. 3). Ce schéma s’applique en particulier au théorème d’inversion locale et des fonctions implicites (cf. CALCUL INFINITÉSIMAL - Calcul à plusieurs variables, chap. 2), aux équations différentielles grâce à la méthode de Picard (cf. équations DIFFÉRENTIELLES, chap. 1, 2 et 4), aux équations intégrales (cf. équations INTÉGRALES, chap. 2) et aux équations aux dérivées partielles.Méthode de compacitéPour étudier les solutions d’une équation du type f (x ) = b , où f est une application continue d’un espace métrique compact K dans un espace de Banach E et où b est un élément donné de E, on construit une suite (x n ) de solutions approchées, c’est-à-dire telles que f (x n ) tende vers b . Dans ces conditions, l’équation f (x ) = b admet au moins une solution et, si l’on suppose en outre l’unicité d’une telle solution a , la suite (x n ) tend vers a .Cette méthode s’applique d’abord aux méthodes d’analyse numérique matricielle (méthode de Jacobi, cf. traitement numérique des MATRICES). Mais elle s’applique aussi aux problèmes d’analyse fonctionnelle. Pour démontrer qu’un ensemble K de fonctions définies sur un espace compact A à valeurs dans un espace E, de dimension finie pour simplifier l’énoncé, est compact, on utilise le théorème suivant, dû à Ascoli. On munit l’espace 暈(A, E) de la norme de la convergence uniforme. Il est alors équivalent de dire:a ) K est compact;b ) K satisfait aux deux conditions suivantes:– K est fermé;– K est équicontinu, c’est-à-dire, 葉s 捻 A, 葉 﨎 礪 0, 說 兀 tel que:
où a n est une constante de normalisation.On notera que, en revanche, le noyau de Dirichlet (cf. SÉRIES TRIGONOMÉTRIQUES, chap. 1) ne convient pas pour toutes les fonctions continues, ce qui se traduit par le fait que la série de Fourier d’une fonction continue peut diverger; cela tient au fait que ce noyau n’est pas positif. Mais la convergence a bien lieu si la fonction est suffisamment régulière, c’est-à-dire si le module de continuité (cf. infra , chap. 7) décroît assez vite.Méthodes de troncatureIl s’agit d’approcher des fonctions définies sur un ouvert U de Rn par des fonctions à support compact contenu dans U. À cet effet, on utilise une suite exhaustive (Kn ) de compacts de U (cf. supra , chap. 1) et on construit une troncature universelle , c’està-dire une suite ( 﨑n ) de fonctions telles que 0 諒 﨑n 諒 1, 﨑n = 1 sur Kn et 﨑n+1 = 0 en dehors de Kn+1 .Dans des questions d’intégration, on peut prendre pour 﨑n la fonction caractéristique de Kn . Dans d’autres problèmes, il faut opérer moins brutalement. Par exemple, en prenant 﨑n continue, on prouve que l’espace vectoriel 留(U) des fonctions continues à support compact contenu dans U est dense dans l’espace vectoriel 暈0(U) des fonctions continues tendant vers 0 au bord de U (muni de la norme de la convergence uniforme) ou encore dans l’espace L2(U) des classes de fonctions de carré intégrable dans U (muni de la norme quadratique).De même, on peut prendre 﨑n de classe C 秊; on prouve alors que l’espace vectoriel 阮(R) des fonctions de classe C 秊 à support compact est dense dans l’espace vectoriel 崙(R) des fonctions de classe C 秊 à décroissance rapide.On peut conjuguer les méthodes de convolution et de troncature pour montrer par exemple que l’espace vectoriel 阮(U) est dense dans l’espace vectoriel 暈(U) pour la convergence uniforme sur tout compact (cf. supra , chap. 1).Méthodes itérativesIl s’agit ici de méthodes où l’algorithme d’approximation de f est défini par une relation de récurrence. En voici trois exemples, dont les deux premiers sont d’importance capitale.Méthode des approximations successivesPour prouver l’existence et l’unicité et étudier les solutions d’équations portant sur des fonctions, on s’inspire du cas des équations numériques en généralisant la méthode des approximations successives [cf. CALCUL NUMÉRIQUE (HISTOIRE DU)] au cadre abstrait des espaces métriques complets (cf. espaces MÉTRIQUES, chap. 3). Ce schéma s’applique en particulier au théorème d’inversion locale et des fonctions implicites (cf. CALCUL INFINITÉSIMAL - Calcul à plusieurs variables, chap. 2), aux équations différentielles grâce à la méthode de Picard (cf. équations DIFFÉRENTIELLES, chap. 1, 2 et 4), aux équations intégrales (cf. équations INTÉGRALES, chap. 2) et aux équations aux dérivées partielles.Méthode de compacitéPour étudier les solutions d’une équation du type f (x ) = b , où f est une application continue d’un espace métrique compact K dans un espace de Banach E et où b est un élément donné de E, on construit une suite (x n ) de solutions approchées, c’est-à-dire telles que f (x n ) tende vers b . Dans ces conditions, l’équation f (x ) = b admet au moins une solution et, si l’on suppose en outre l’unicité d’une telle solution a , la suite (x n ) tend vers a .Cette méthode s’applique d’abord aux méthodes d’analyse numérique matricielle (méthode de Jacobi, cf. traitement numérique des MATRICES). Mais elle s’applique aussi aux problèmes d’analyse fonctionnelle. Pour démontrer qu’un ensemble K de fonctions définies sur un espace compact A à valeurs dans un espace E, de dimension finie pour simplifier l’énoncé, est compact, on utilise le théorème suivant, dû à Ascoli. On munit l’espace 暈(A, E) de la norme de la convergence uniforme. Il est alors équivalent de dire:a ) K est compact;b ) K satisfait aux deux conditions suivantes:– K est fermé;– K est équicontinu, c’est-à-dire, 葉s 捻 A, 葉 﨎 礪 0, 說 兀 tel que: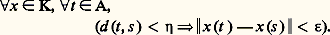 Lorsque, par exemple, A est un intervalle [a , b ] de R et E = C, l’hypothèse d’équicontinuité est satisfaite lorsque K est constitué des fonctions x de classe C1 telles que 瑩Dx 瑩 size=1秊 諒 廓, ou, plus généralement si Dx est de carré intégrable et si 咽b a |Dx |2 諒 廓.Méthode de Padé: fractions continuesOn opère par analogie avec le développement des nombres en fraction continue (cf. approximations DIOPHANTIENNES, chap. 2).Une telle méthode se décrit à l’aide du schéma général suivant.Soit f une fonction définie sur un intervalle I de centre O. Un développement de f en fraction continue est de la forme:
Lorsque, par exemple, A est un intervalle [a , b ] de R et E = C, l’hypothèse d’équicontinuité est satisfaite lorsque K est constitué des fonctions x de classe C1 telles que 瑩Dx 瑩 size=1秊 諒 廓, ou, plus généralement si Dx est de carré intégrable et si 咽b a |Dx |2 諒 廓.Méthode de Padé: fractions continuesOn opère par analogie avec le développement des nombres en fraction continue (cf. approximations DIOPHANTIENNES, chap. 2).Une telle méthode se décrit à l’aide du schéma général suivant.Soit f une fonction définie sur un intervalle I de centre O. Un développement de f en fraction continue est de la forme: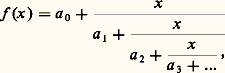 qu’on écrit avec la notation:
qu’on écrit avec la notation: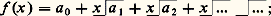 cela signifie que les fractions rationnelles:
cela signifie que les fractions rationnelles: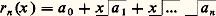 convergent vers f uniformément sur tout compact de I. Cette méthode a été étudiée systématiquement par Padé (1892). Déjà, Euler avait montré que:
convergent vers f uniformément sur tout compact de I. Cette méthode a été étudiée systématiquement par Padé (1892). Déjà, Euler avait montré que: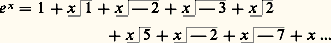 et avait déduit de développements analogues l’irrationalité de e . Lambert avait obtenu de même le développement en fraction continue de tanx et en avait déduit l’irrationalité de 神. Avec le développement de l’analyse numérique, lié à celui des ordinateurs, ce type d’approximation des fonctions transcendantes élémentaires par des fractions continues a connu un regain d’intérêt. Ainsi, pour le calcul de e x , avec 漣 Lg 連2 諒 x 諒 Lg 連2, la formule:
et avait déduit de développements analogues l’irrationalité de e . Lambert avait obtenu de même le développement en fraction continue de tanx et en avait déduit l’irrationalité de 神. Avec le développement de l’analyse numérique, lié à celui des ordinateurs, ce type d’approximation des fonctions transcendantes élémentaires par des fractions continues a connu un regain d’intérêt. Ainsi, pour le calcul de e x , avec 漣 Lg 連2 諒 x 諒 Lg 連2, la formule: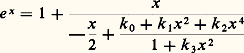 avec k 0 = 1,000 000 000 000 327 1, k 1 = 0,107 135 066 456 464 2, k 2 = 0,000 594 589 869 018 8 et k 3 = 0,023 801 733 157 418 6, fournit une précision de 1,4 練 10-14. Pour obtenir la même précision avec des polynômes, il faudrait monter au degré 15.Mais cette méthode s’applique aussi à des problèmes d’ordre plus théorique. Soit par exemple f une fonction méromorphe dans un disque de centre O et régulière à l’origine. Alors f est développable en série de Taylor:
avec k 0 = 1,000 000 000 000 327 1, k 1 = 0,107 135 066 456 464 2, k 2 = 0,000 594 589 869 018 8 et k 3 = 0,023 801 733 157 418 6, fournit une précision de 1,4 練 10-14. Pour obtenir la même précision avec des polynômes, il faudrait monter au degré 15.Mais cette méthode s’applique aussi à des problèmes d’ordre plus théorique. Soit par exemple f une fonction méromorphe dans un disque de centre O et régulière à l’origine. Alors f est développable en série de Taylor: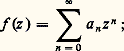 on peut espérer que, si l’on approche f par des fractions rationnelles au voisinage de 0,
on peut espérer que, si l’on approche f par des fractions rationnelles au voisinage de 0,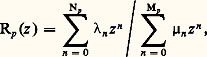 alors les pôles de Rp vont approcher les pôles de f . Plus précisément, on calcule les coefficientsn et 猪n en résolvant le système linéaire obtenu en identifiant les développements limités d’ordre Mp + Np de f et de Rp à l’origine et on écrit alors Rp sous forme de fraction continue. Cette méthode est cependant souvent utilisée de manière expérimentale dans les applications et donne des résultats fiables.Méthodes de projectionLes méthodes de projection peuvent être décrites par le schéma général suivant. On considère un espace E de fonctions, normé par exemple, et une suite croissante de sous-espaces vectoriels fermés En dont la réunion soit dense dans E. Pour chaque entier n , on se donne un projecteur continu u n de E sur En . On essaie alors d’approcher un élément f de E par la suite f n = u n (f ).Le cas des projecteurs orthogonaux est un exemple fondamental: l’espace vectoriel E est hilbertien, muni d’une base hilbertienne (e 0, e 1 ..., e n , ...), En est le sous-espace engendré par (e 0, ..., e n ) et u n est le projecteur orthogonal de E sur En . Dans ces conditions, f n converge toujours vers f (cf. espace de HILBERT). Le cas des séries de Fourier est celui où E est l’espace vectoriel des fonctions 1-périodiques de carré intégrable sur [0, 1] muni de la norme quadratique et où, pour tout n , e n (t ) = exp2i 神nt [cf. SÉRIES TRIGONOMÉTRIQUES]. De même, lorsque E est l’espace vectoriel L2([ 漣 1, 1]) et que e n est le polynôme de Legendre Ln de degré n , on obtient ainsi un procédé canonique d’approximation en moyenne quadratique de f par des polynômes u n (f ). Le cas plus général des développements en série de fonctions orthogonales entre dans ce cadre (cf. polynômes ORTHOGONAUX), ainsi que la méthode de Galerkine (cf. équations aux DÉRIVÉES PARTIELLES - Analyse numérique des équations aux dérivées partielles, chap. 1).Ces résultats montrent tout l’intérêt des normes quadratiques 2 sur les espaces de fonctions; en effet, nous verrons au chapitre 8 que, pour ce type de problème, le comportement de la norme N size=1秊 est beaucoup moins agréable.Emploi d’extremumsDe nombreuses questions d’analyse fonctionnelle peuvent se ramener à la recherche d’extremums (problèmes variationnels, problèmes aux limites dans les équations aux dérivées partielles...) que l’on peut souvent schématiser de la façon suivante. Soit C une partie convexe d’un espace hilbertien E et x un élément de E. Il existe alors au plus un point z de C tel que d (x , z ) = d (x , C). Pour étudier l’existence de z et approcher ce point, on construit une suite (z n ) d’éléments de C telle que limd (x , z n ) = d (x , C). On montre n 轢秊que cette suite est une suite de Cauchy. La convergence de la suite (z n ) est alors assurée lorsque C est une partie fermée de E.5. Interpolation et discrétisationPosition du problèmeCe sont les problèmes de tabulation numérique des fonctions transcendantes élémentaires (lignes trigonométriques, logarithmes) et, à partir du XVIIe siècle, le calcul approché des intégrales et des dérivées qui ont été à l’origine du développement des méthodes interpolatoires [cf. CALCUL NUMÉRIQUE (HISTOIRE DU)]. D’autre part, dans de nombreux phénomènes continus intervenant en sciences physiques, décrits par exemple à l’aide d’une fonction, on ne connaît les valeurs de cette fonction qu’en un certain nombre de points qui correspondent aux mesures effectuées. Les problèmes issus de l’astronomie, en particulier la détermination de la trajectoire des planètes, ont aussi joué un rôle moteur, comme en témoignent notamment les travaux d’Euler, Lagrange, Legendre, Laplace et Gauss.Dans tous les cas, le phénomène continu est remplacé par un phénomène discret. Plus précisément, supposons que le phénomène continu est décrit par une fonction numérique f d’une variable réelle. On se donne une subdivision S de l’intervalle [ 見, 廓], c’està-dire une suite croissante ( 見0, 見1, ..., 見n ) de points de [ 見, 廓]; le module de la subdivision S est le nombre:
alors les pôles de Rp vont approcher les pôles de f . Plus précisément, on calcule les coefficientsn et 猪n en résolvant le système linéaire obtenu en identifiant les développements limités d’ordre Mp + Np de f et de Rp à l’origine et on écrit alors Rp sous forme de fraction continue. Cette méthode est cependant souvent utilisée de manière expérimentale dans les applications et donne des résultats fiables.Méthodes de projectionLes méthodes de projection peuvent être décrites par le schéma général suivant. On considère un espace E de fonctions, normé par exemple, et une suite croissante de sous-espaces vectoriels fermés En dont la réunion soit dense dans E. Pour chaque entier n , on se donne un projecteur continu u n de E sur En . On essaie alors d’approcher un élément f de E par la suite f n = u n (f ).Le cas des projecteurs orthogonaux est un exemple fondamental: l’espace vectoriel E est hilbertien, muni d’une base hilbertienne (e 0, e 1 ..., e n , ...), En est le sous-espace engendré par (e 0, ..., e n ) et u n est le projecteur orthogonal de E sur En . Dans ces conditions, f n converge toujours vers f (cf. espace de HILBERT). Le cas des séries de Fourier est celui où E est l’espace vectoriel des fonctions 1-périodiques de carré intégrable sur [0, 1] muni de la norme quadratique et où, pour tout n , e n (t ) = exp2i 神nt [cf. SÉRIES TRIGONOMÉTRIQUES]. De même, lorsque E est l’espace vectoriel L2([ 漣 1, 1]) et que e n est le polynôme de Legendre Ln de degré n , on obtient ainsi un procédé canonique d’approximation en moyenne quadratique de f par des polynômes u n (f ). Le cas plus général des développements en série de fonctions orthogonales entre dans ce cadre (cf. polynômes ORTHOGONAUX), ainsi que la méthode de Galerkine (cf. équations aux DÉRIVÉES PARTIELLES - Analyse numérique des équations aux dérivées partielles, chap. 1).Ces résultats montrent tout l’intérêt des normes quadratiques 2 sur les espaces de fonctions; en effet, nous verrons au chapitre 8 que, pour ce type de problème, le comportement de la norme N size=1秊 est beaucoup moins agréable.Emploi d’extremumsDe nombreuses questions d’analyse fonctionnelle peuvent se ramener à la recherche d’extremums (problèmes variationnels, problèmes aux limites dans les équations aux dérivées partielles...) que l’on peut souvent schématiser de la façon suivante. Soit C une partie convexe d’un espace hilbertien E et x un élément de E. Il existe alors au plus un point z de C tel que d (x , z ) = d (x , C). Pour étudier l’existence de z et approcher ce point, on construit une suite (z n ) d’éléments de C telle que limd (x , z n ) = d (x , C). On montre n 轢秊que cette suite est une suite de Cauchy. La convergence de la suite (z n ) est alors assurée lorsque C est une partie fermée de E.5. Interpolation et discrétisationPosition du problèmeCe sont les problèmes de tabulation numérique des fonctions transcendantes élémentaires (lignes trigonométriques, logarithmes) et, à partir du XVIIe siècle, le calcul approché des intégrales et des dérivées qui ont été à l’origine du développement des méthodes interpolatoires [cf. CALCUL NUMÉRIQUE (HISTOIRE DU)]. D’autre part, dans de nombreux phénomènes continus intervenant en sciences physiques, décrits par exemple à l’aide d’une fonction, on ne connaît les valeurs de cette fonction qu’en un certain nombre de points qui correspondent aux mesures effectuées. Les problèmes issus de l’astronomie, en particulier la détermination de la trajectoire des planètes, ont aussi joué un rôle moteur, comme en témoignent notamment les travaux d’Euler, Lagrange, Legendre, Laplace et Gauss.Dans tous les cas, le phénomène continu est remplacé par un phénomène discret. Plus précisément, supposons que le phénomène continu est décrit par une fonction numérique f d’une variable réelle. On se donne une subdivision S de l’intervalle [ 見, 廓], c’està-dire une suite croissante ( 見0, 見1, ..., 見n ) de points de [ 見, 廓]; le module de la subdivision S est le nombre: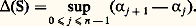 Lorsque 見0 = 見, 見n = 廓 et, pour tout j , 見j+1 漣 見j = ( 廓 漣 見)/n , on dit que la subdivision est à pas constant, et (S) = ( 廓 漣 見)/n s’appelle le pas de S.Dans ces conditions, on associe à S la suite finie (f ( 見0), ..., f ( 見n )). Nous dirons qu’il s’agit d’une discrétisation de f (cf. analyse NUMÉRIQUE). Le problème est alors de savoir dans quelle mesure on peut reconstituer f à partir des phénomènes discrétisés associés. À cet effet, on interpole la suite précédente par une fonction simple, par exemple une fonction polynomiale que nous noterons PS(f ), de degré 諒 n , prenant aux points 見j les mêmes valeurs que f . Dans le cas où S est à pas constant, cette méthode a été élaborée dès le XVIIe siècle, notamment par Newton et Gregory, dans le cadre du calcul des différences finies (cf. infra ). L’étude du cas général a été ébauchée par Newton et reprise par Lagrange, Cauchy et Hermite.Il s’agit alors d’estimer la différence f 漣 PS(f ), par exemple en majorant N size=1秊(f 漣 PS(f )), et d’étudier l’influence de la taille de l’intervalle [ 見, 廓], du choix de S et de la régularité de f sur la qualité de l’approximation. Il arrive souvent qu’on ne s’intéresse pas directement à f mais à la valeur d’une forme linéaire sur f . Pour ce type de problème, d’autres normes s’imposent: norme 1 pour les intégrales, normes f 料 N size=1秊(f ) + N size=1秊(Df ) pour les dérivées. Dans les phénomènes physiques, les normes 2 interviennent souvent au titre de l’énergie.On peut aussi se demander s’il est possible de reconstituer f comme limite de fonctions PS(f ) en raffinant les subdivisions, c’est-àdire en faisant tendre le module (S) vers 0. Mais cette question présente des difficultés (cf. infra , Interpolation polynomiale ). C’est pourquoi on a recours à un procédé plus élaboré: on se donne f sur un intervalle [a , b ], on découpe cet intervalle en p intervalles de longueur (b 漣 a )/p et, sur chacun de ces intervalles notés [ 見, 廓], on approche f par PS(f ). Le problème est alors de savoir comment on peut jouer sur les entiers n et p pour obtenir des approximations efficaces. Dans ce schéma plus élaboré, f est approchée sur [a , b ] par une fonction 﨏 continue et polynomiale par morceaux. On peut imposer en outre à 﨏 des conditions de régularité plus fortes aux p 漣 1 points de subdivision de [a , b ], ce qui conduit par exemple à la théorie des fonctions spline (cf. infra , Interpolation polynomiale par morceaux ). Les méthodes de discrétisation s’appliquent aussi à la recherche de solutions approchées d’équations différentielles, grâce à l’emploi d’équations aux différences finies (cf. équations DIFFÉRENTIELLES, chap. 7); plus récemment, le développement des calculs sur ordinateurs a permis de les appliquer avec succès aux équations aux dérivées partielles (cf. équations aux DÉRIVÉES PARTIELLES - Analyse numérique, chap. 1).Nous commencerons par décrire les principales méthodes d’interpolation polynomiale et nous aborderons ensuite l’interpolation par les fonctions polynomiales par morceaux.Interpolation polynomialeInterpolation de LagrangeÉtant donné un élément b = ( 廓0, ..., 廓n ) 捻 Cn+1 , on veut étudier les polynômes P à coefficients complexes tels que, pour tout j ,
Lorsque 見0 = 見, 見n = 廓 et, pour tout j , 見j+1 漣 見j = ( 廓 漣 見)/n , on dit que la subdivision est à pas constant, et (S) = ( 廓 漣 見)/n s’appelle le pas de S.Dans ces conditions, on associe à S la suite finie (f ( 見0), ..., f ( 見n )). Nous dirons qu’il s’agit d’une discrétisation de f (cf. analyse NUMÉRIQUE). Le problème est alors de savoir dans quelle mesure on peut reconstituer f à partir des phénomènes discrétisés associés. À cet effet, on interpole la suite précédente par une fonction simple, par exemple une fonction polynomiale que nous noterons PS(f ), de degré 諒 n , prenant aux points 見j les mêmes valeurs que f . Dans le cas où S est à pas constant, cette méthode a été élaborée dès le XVIIe siècle, notamment par Newton et Gregory, dans le cadre du calcul des différences finies (cf. infra ). L’étude du cas général a été ébauchée par Newton et reprise par Lagrange, Cauchy et Hermite.Il s’agit alors d’estimer la différence f 漣 PS(f ), par exemple en majorant N size=1秊(f 漣 PS(f )), et d’étudier l’influence de la taille de l’intervalle [ 見, 廓], du choix de S et de la régularité de f sur la qualité de l’approximation. Il arrive souvent qu’on ne s’intéresse pas directement à f mais à la valeur d’une forme linéaire sur f . Pour ce type de problème, d’autres normes s’imposent: norme 1 pour les intégrales, normes f 料 N size=1秊(f ) + N size=1秊(Df ) pour les dérivées. Dans les phénomènes physiques, les normes 2 interviennent souvent au titre de l’énergie.On peut aussi se demander s’il est possible de reconstituer f comme limite de fonctions PS(f ) en raffinant les subdivisions, c’est-àdire en faisant tendre le module (S) vers 0. Mais cette question présente des difficultés (cf. infra , Interpolation polynomiale ). C’est pourquoi on a recours à un procédé plus élaboré: on se donne f sur un intervalle [a , b ], on découpe cet intervalle en p intervalles de longueur (b 漣 a )/p et, sur chacun de ces intervalles notés [ 見, 廓], on approche f par PS(f ). Le problème est alors de savoir comment on peut jouer sur les entiers n et p pour obtenir des approximations efficaces. Dans ce schéma plus élaboré, f est approchée sur [a , b ] par une fonction 﨏 continue et polynomiale par morceaux. On peut imposer en outre à 﨏 des conditions de régularité plus fortes aux p 漣 1 points de subdivision de [a , b ], ce qui conduit par exemple à la théorie des fonctions spline (cf. infra , Interpolation polynomiale par morceaux ). Les méthodes de discrétisation s’appliquent aussi à la recherche de solutions approchées d’équations différentielles, grâce à l’emploi d’équations aux différences finies (cf. équations DIFFÉRENTIELLES, chap. 7); plus récemment, le développement des calculs sur ordinateurs a permis de les appliquer avec succès aux équations aux dérivées partielles (cf. équations aux DÉRIVÉES PARTIELLES - Analyse numérique, chap. 1).Nous commencerons par décrire les principales méthodes d’interpolation polynomiale et nous aborderons ensuite l’interpolation par les fonctions polynomiales par morceaux.Interpolation polynomialeInterpolation de LagrangeÉtant donné un élément b = ( 廓0, ..., 廓n ) 捻 Cn+1 , on veut étudier les polynômes P à coefficients complexes tels que, pour tout j , À cet effet, on introduit l’application linéaire u : C[X]Cn+1 qui à tout polynôme P associe (P( 見0), ..., P( 見n )). Les équations (1) s’écrivent alors sous la forme:
À cet effet, on introduit l’application linéaire u : C[X]Cn+1 qui à tout polynôme P associe (P( 見0), ..., P( 見n )). Les équations (1) s’écrivent alors sous la forme: Le noyau de u est constitué des polynômes P qui s’annulent en tout point 見j , c’est-à-dire qui sont divisibles par:
Le noyau de u est constitué des polynômes P qui s’annulent en tout point 見j , c’est-à-dire qui sont divisibles par: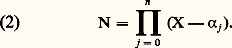 Ce polynôme N, dont la donnée équivaut à celle du système S, joue un rôle fondamental dans la théorie de l’interpolation; on l’appelle le noyau interpolateur associé à S. Le théorème de division euclidienne des polynômes montre que C[X] = Keru 簾 En , où En est l’espace vectoriel des polynômes de degré 諒 n .L’application linéaire u induit un isomorphisme de En sur Cn+1 . Ainsi, il existe un polynôme Pb de degré 諒 n et un seul tel que, pour tout j , on ait Pb ( 見j ) = 廓j . Les solutions de (1) sont alors les polynômes P de la forme P = Pb + QN, où Q 捻 C[X].En particulier, pour tout i , il existe un polynôme Li de En et un seul tel que:
Ce polynôme N, dont la donnée équivaut à celle du système S, joue un rôle fondamental dans la théorie de l’interpolation; on l’appelle le noyau interpolateur associé à S. Le théorème de division euclidienne des polynômes montre que C[X] = Keru 簾 En , où En est l’espace vectoriel des polynômes de degré 諒 n .L’application linéaire u induit un isomorphisme de En sur Cn+1 . Ainsi, il existe un polynôme Pb de degré 諒 n et un seul tel que, pour tout j , on ait Pb ( 見j ) = 廓j . Les solutions de (1) sont alors les polynômes P de la forme P = Pb + QN, où Q 捻 C[X].En particulier, pour tout i , il existe un polynôme Li de En et un seul tel que: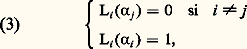 à savoir le polynôme:
à savoir le polynôme: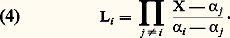 Dans ces conditions, on a:
Dans ces conditions, on a: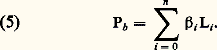 Soit maintenant f une fonction continue à valeurs complexes sur [ 見, 廓], et b = (f ( 見0), ..., f ( 見n )); le polynôme Pb s’appelle le polynôme d’interpolation de Lagrange de f associé à S et se note LS(f ) (fig. 4). Ainsi, LS(f ) est l’unique polynôme de degré inférieur à n tel que, pour tout j ,
Soit maintenant f une fonction continue à valeurs complexes sur [ 見, 廓], et b = (f ( 見0), ..., f ( 見n )); le polynôme Pb s’appelle le polynôme d’interpolation de Lagrange de f associé à S et se note LS(f ) (fig. 4). Ainsi, LS(f ) est l’unique polynôme de degré inférieur à n tel que, pour tout j ,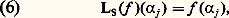 et:
et: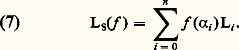 En outre, l’application u S: f 料 LS(f ) est un projecteur de 暈([a , b ]) sur le sous-espace vectoriel En .On peut estimer la précision de l’approximation de f par LS(f ), grâce au théorème de division des fonctions différentiables (cf. supra ); on démontre que, si f est de classe Cn+1 sur [ 見, 廓], alors, pour tout t 捻 [ 見, 廓], on a la majoration:
En outre, l’application u S: f 料 LS(f ) est un projecteur de 暈([a , b ]) sur le sous-espace vectoriel En .On peut estimer la précision de l’approximation de f par LS(f ), grâce au théorème de division des fonctions différentiables (cf. supra ); on démontre que, si f est de classe Cn+1 sur [ 見, 廓], alors, pour tout t 捻 [ 見, 廓], on a la majoration: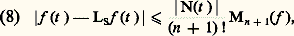 et, en particulier:
et, en particulier: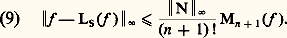 Ces majorations ne peuvent pas être améliorées, car (8) et (9) sont des égalités lorsque f est le noyau interpolateur N.Supposons maintenant que f est de classe C 秊; donnons-nous une suite (Sn ) de subdivisions telle que (Sn )0 et notons plus simplement Ln (f ) le polynôme interpolateur de f associé à Sn . Dans ces conditions:
Ces majorations ne peuvent pas être améliorées, car (8) et (9) sont des égalités lorsque f est le noyau interpolateur N.Supposons maintenant que f est de classe C 秊; donnons-nous une suite (Sn ) de subdivisions telle que (Sn )0 et notons plus simplement Ln (f ) le polynôme interpolateur de f associé à Sn . Dans ces conditions: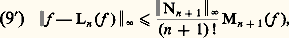 où Nn+1 est le noyau interpolateur associé à Sn , qui est de degré n + 1.
où Nn+1 est le noyau interpolateur associé à Sn , qui est de degré n + 1.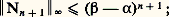 mais Mn+1 (f ) peut croître très vite, si bien que la majoration (9 ) ne permet de prouver la convergence que si f est holomorphe dans un disque ouvert contenant l’intervalle [ 見, 廓]. D’ailleurs, dans le cas des subdivisions à pas constant ( 廓 漣 見)/n , il peut arriver, contrairement à toute attente, que f soit analytique sur R mais que Ln (f ) ne converge pas vers f sur [ 見, 廓]. C’est le cas par exemple si [ 見, 廓] = [ 漣 1, + 1], f (t ) = 1/(1 + a 2t 2) (fig. 5) et a assez grand, par exemple a 閭 2. On observera qu’ici i /a et 漣 i /a sont des pôles de f (z ) = 1/(1 + a 2z 2), si bien que la condition d’holomorphie évoquée ci-dessus n’est pas réalisée. Ce type de phénomène a été découvert par Runge et Borel.Pour remédier à ce défaut, on peut essayer de choisir les subdivisions Sn de telle sorte que 瑩Nn+1 瑩 size=1秊 soit minimale, ce qui a lieu lorsque Nn est le n -ième polynôme Tn de Tchebychev. Pour [ 見, 廓] = [ 漣 1, + 1], on a:
mais Mn+1 (f ) peut croître très vite, si bien que la majoration (9 ) ne permet de prouver la convergence que si f est holomorphe dans un disque ouvert contenant l’intervalle [ 見, 廓]. D’ailleurs, dans le cas des subdivisions à pas constant ( 廓 漣 見)/n , il peut arriver, contrairement à toute attente, que f soit analytique sur R mais que Ln (f ) ne converge pas vers f sur [ 見, 廓]. C’est le cas par exemple si [ 見, 廓] = [ 漣 1, + 1], f (t ) = 1/(1 + a 2t 2) (fig. 5) et a assez grand, par exemple a 閭 2. On observera qu’ici i /a et 漣 i /a sont des pôles de f (z ) = 1/(1 + a 2z 2), si bien que la condition d’holomorphie évoquée ci-dessus n’est pas réalisée. Ce type de phénomène a été découvert par Runge et Borel.Pour remédier à ce défaut, on peut essayer de choisir les subdivisions Sn de telle sorte que 瑩Nn+1 瑩 size=1秊 soit minimale, ce qui a lieu lorsque Nn est le n -ième polynôme Tn de Tchebychev. Pour [ 見, 廓] = [ 漣 1, + 1], on a: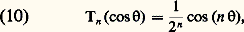 auquel cas:
auquel cas: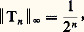 et les points 見j sont:
et les points 見j sont: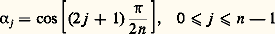 (fig. 6). Ainsi, les points 見j sont les projections sur [ 漣 1, + 1] des sommets du polygone régulier à 2 n côtés. Ces points s’accumulent donc aux deux extrémités de l’intervalle [ 漣 1, + 1]. Nous verrons au chapitre 7, en utilisant une estimation beaucoup plus fine que (9 ), que la convergence de Ln (f ) vers f est alors assurée sous des conditions très larges, par exemple si f est de classe C1.Cependant, cette convergence n’a pas lieu pour toutes les fonctions continues. En effet, d’après un théorème de Faber, quelle que soit la suite (Sn ), il existe une fonction continue f telle que 瑩Ln (f ) 瑩 size=1秊 tende vers + 秊. Ce résultat est un des exemples cités par Banach et Steinhaus comme étant à l’origine du théorème qui porte leur nom (cf. espaces vectoriels NORMÉS, chap. 4).Interpolation de HermiteIl s’agit du cas plus général où l’on impose au polynôme interpolateur des contacts d’ordre donné avec la fonction f aux points 見j . On se donne cette fois une suite ( 見0, ..., 見r ) de points de [ 見, 廓], et une suite (n 0, ..., n r ) d’entiers strictement positifs. On pose:
(fig. 6). Ainsi, les points 見j sont les projections sur [ 漣 1, + 1] des sommets du polygone régulier à 2 n côtés. Ces points s’accumulent donc aux deux extrémités de l’intervalle [ 漣 1, + 1]. Nous verrons au chapitre 7, en utilisant une estimation beaucoup plus fine que (9 ), que la convergence de Ln (f ) vers f est alors assurée sous des conditions très larges, par exemple si f est de classe C1.Cependant, cette convergence n’a pas lieu pour toutes les fonctions continues. En effet, d’après un théorème de Faber, quelle que soit la suite (Sn ), il existe une fonction continue f telle que 瑩Ln (f ) 瑩 size=1秊 tende vers + 秊. Ce résultat est un des exemples cités par Banach et Steinhaus comme étant à l’origine du théorème qui porte leur nom (cf. espaces vectoriels NORMÉS, chap. 4).Interpolation de HermiteIl s’agit du cas plus général où l’on impose au polynôme interpolateur des contacts d’ordre donné avec la fonction f aux points 見j . On se donne cette fois une suite ( 見0, ..., 見r ) de points de [ 見, 廓], et une suite (n 0, ..., n r ) d’entiers strictement positifs. On pose: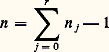 et:
et: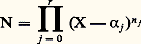 Lorsque f est de classe Cn+1 sur [ 見, 廓], il existe un polynôme LS(f ) de degré 諒 n et un seul tel que, pour tout j , 0 諒 j 諒 r , et tout k , 0 諒 k 諒 n j 漣 1, on ait:
Lorsque f est de classe Cn+1 sur [ 見, 廓], il existe un polynôme LS(f ) de degré 諒 n et un seul tel que, pour tout j , 0 諒 j 諒 r , et tout k , 0 諒 k 諒 n j 漣 1, on ait: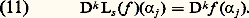 En outre, pour tout t 捻 [ 見, 廓],
En outre, pour tout t 捻 [ 見, 廓],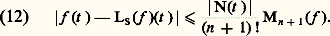 Le polynôme LS(f ) est le polynôme d’interpolation de Hermite associé à S. Le cas de Lagrange correspond à n j = 1, tandis que la formule de Taylor correspond à r = 1 et n 0 = n + 1, c’est-à-dire:
Le polynôme LS(f ) est le polynôme d’interpolation de Hermite associé à S. Le cas de Lagrange correspond à n j = 1, tandis que la formule de Taylor correspond à r = 1 et n 0 = n + 1, c’est-à-dire: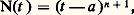 et:
et: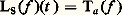 Dans le cas où n j = 2, c’est-à-dire:
Dans le cas où n j = 2, c’est-à-dire: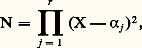 on impose à LS(f ) d’avoir un contact à l’ordre 1 en chaque point interpolateur 見j . Ce cas intervient notamment dans les méthodes d’optimisation pour le calcul approché des intégrales (cf. analyse NUMÉRIQUE, chap. 2). La positivité du noyau N joue un rôle essentiel dans ce genre de question.Différences diviséesL’expression du polynôme interpolatoire de Lagrange (formule (7)) a l’avantage de faire intervenir de manière symétrique les points de subdivision, mais elle est mal adaptée au calcul numérique, d’autant plus que l’adjonction de points interpolateurs supplémentaires oblige à recommencer entièrement les calculs. Newton avait procédé en utilisant une autre base de l’espace vectoriel des polynômes de degré 諒 n , à savoir D0 = 1, D1 = X 漣 見0, D2 = (X 漣 見0)(X 漣 見1), ..., Dn = (X 漣 見0) ... (X 漣 見n-1 ); ici la matrice de passage de la base canonique 1, X, ..., Xn à cette base est beaucoup plus simple que dans le cas de Lagrange car elle est triangulaire.Pour obtenir la décomposition dans cette base du polynôme interpolateur LS(f ), on introduit les différences divisées de f relatives à S, définies par les relations de récurrence:
on impose à LS(f ) d’avoir un contact à l’ordre 1 en chaque point interpolateur 見j . Ce cas intervient notamment dans les méthodes d’optimisation pour le calcul approché des intégrales (cf. analyse NUMÉRIQUE, chap. 2). La positivité du noyau N joue un rôle essentiel dans ce genre de question.Différences diviséesL’expression du polynôme interpolatoire de Lagrange (formule (7)) a l’avantage de faire intervenir de manière symétrique les points de subdivision, mais elle est mal adaptée au calcul numérique, d’autant plus que l’adjonction de points interpolateurs supplémentaires oblige à recommencer entièrement les calculs. Newton avait procédé en utilisant une autre base de l’espace vectoriel des polynômes de degré 諒 n , à savoir D0 = 1, D1 = X 漣 見0, D2 = (X 漣 見0)(X 漣 見1), ..., Dn = (X 漣 見0) ... (X 漣 見n-1 ); ici la matrice de passage de la base canonique 1, X, ..., Xn à cette base est beaucoup plus simple que dans le cas de Lagrange car elle est triangulaire.Pour obtenir la décomposition dans cette base du polynôme interpolateur LS(f ), on introduit les différences divisées de f relatives à S, définies par les relations de récurrence: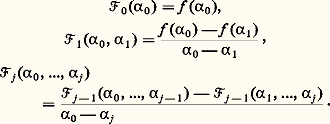 Dans ces conditions, on a la formule:
Dans ces conditions, on a la formule: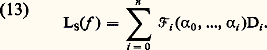 En outre, le reste est donné par la relation:
En outre, le reste est donné par la relation: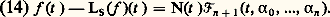 L’adjonction à S d’un point supplémentaire ne modifie pas les différences divisées précédentes. En outre, la différence divisée 杻j est une fonction symétrique de 見0, ..., 見j , car:
L’adjonction à S d’un point supplémentaire ne modifie pas les différences divisées précédentes. En outre, la différence divisée 杻j est une fonction symétrique de 見0, ..., 見j , car: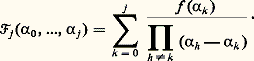 Subdivisions à pas constantLorsque S est une subdivision de [ 見, 廓] à pas constant h = ( 廓 漣 見)/n , il est commode d’étudier d’abord le cas où h = 1 et 見 = 0, et donc 廓 = n 漣 1; le noyau interpolateur s’écrit alors:
Subdivisions à pas constantLorsque S est une subdivision de [ 見, 廓] à pas constant h = ( 廓 漣 見)/n , il est commode d’étudier d’abord le cas où h = 1 et 見 = 0, et donc 廓 = n 漣 1; le noyau interpolateur s’écrit alors: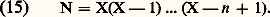 Pour calculer le polynôme interpolateur LS(g ), où g est définie sur [0, n 漣 1], on introduit l’opérateur de Bernoulli , à savoir l’endomorphisme de C[X] défini par la relation:
Pour calculer le polynôme interpolateur LS(g ), où g est définie sur [0, n 漣 1], on introduit l’opérateur de Bernoulli , à savoir l’endomorphisme de C[X] défini par la relation: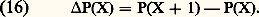 L’étude de cet endomorphisme conduit à introduire une base de C[X] adaptée à , définie par les relations de récurrence:
L’étude de cet endomorphisme conduit à introduire une base de C[X] adaptée à , définie par les relations de récurrence: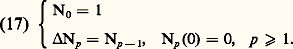 Ces polynômes sont donnés par les relations:
Ces polynômes sont donnés par les relations: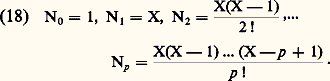 Les polynômes Np s’appellent polynômes de Newton ; on remarquera que Np = (1/p !) Dp . Dans ces conditions, tout polynome P se décompose sous la forme:
Les polynômes Np s’appellent polynômes de Newton ; on remarquera que Np = (1/p !) Dp . Dans ces conditions, tout polynome P se décompose sous la forme: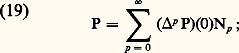 c’est la formule de Newton-Gregory, analogue à la formule de Taylor qui est, elle, relative à l’opérateur de dérivation D, la base adaptée étant alors 1, X, ..., 1/(p !) Xp .Appliquant la relation (19) à LS(g ), on obtient:
c’est la formule de Newton-Gregory, analogue à la formule de Taylor qui est, elle, relative à l’opérateur de dérivation D, la base adaptée étant alors 1, X, ..., 1/(p !) Xp .Appliquant la relation (19) à LS(g ), on obtient: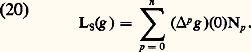 Le calcul des différences successives dites non divisées ( p g )(0) est très facile. Le cas d’une fonction f définie sur [ 見, 廓] se ramène au cas précédent par changement de variable affine, en introduisant g (u ) = f ( 見 + ( 廓 漣 見)u).On peut développer une théorie entièrement analogue en introduisant à côté de l’opérateur de Bernoulli progressif , l’opérateur régressif 暴 défini par:
Le calcul des différences successives dites non divisées ( p g )(0) est très facile. Le cas d’une fonction f définie sur [ 見, 廓] se ramène au cas précédent par changement de variable affine, en introduisant g (u ) = f ( 見 + ( 廓 漣 見)u).On peut développer une théorie entièrement analogue en introduisant à côté de l’opérateur de Bernoulli progressif , l’opérateur régressif 暴 défini par: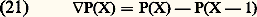 et l’opérateur symétrique:
et l’opérateur symétrique: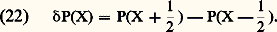 Les opérateurs , 暴 et 嗀 peuvent s’exprimer à l’aide des opérateurs de translation:
Les opérateurs , 暴 et 嗀 peuvent s’exprimer à l’aide des opérateurs de translation: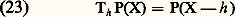 par les formules
par les formules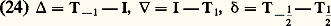 on peut alors développer un calcul symbolique sur ces opérateurs et l’opérateur de dérivation D. Ainsi, la formule de Taylor traduit la formule symbolique Th = exph D. Ce calcul, ébauché par Leibniz, a été systématisé par Lagrange et Laplace ; à la fin du XIXe siècle, il a été repris dans le cadre général de la théorie des opérateurs de convolution, c’est-à-dire des opérateurs qui commutent aux translations.GénéralisationsLe problème de l’interpolation se pose aussi pour les fonctions périodiques, auquel cas les fonctions polynomiales sont remplacées par des polynômes trigonométriques. Ces deux exemples se placent dans la théorie générale des systèmes de Tchebychev : on se donne un sous-espace En de dimension n + 1 de l’espace 暈([ 見, 廓]) qui est régulier , c’est-à-dire tel que tout élément de En qui s’annule en au moins n + 1 points est nul. Étant donné une base 﨏0, 﨏1, ..., 﨏n de En , on interpole f par une combinaison linéaire de ces fonctions. On peut montrer, en particulier, que l’espace vectoriel des solutions d’une équation différentielle linéaire sans second membre d’ordre n + 1 est régulier.Interpolation polynomiale par morceauxThéorie classiqueOn considère cette fois une fonction f continue sur un intervalle [a , b ], que l’on découpe en p intervalles [t j , t j+1 ] de longueur (b 漣 a )/p et, sur chacun de ces intervalles, on effectue une interpolation de Lagrange ou de Hermite de f , par des polynômes de degré 諒 n . En pratique, n est fixé et assez petit pour éviter les phénomènes du type de Runge. Il s’agit alors d’étudier la convergence de la suite ( 﨏p ) des fonctions polynomiales par morceaux ainsi obtenues vers la fonction f et la rapidité de convergence en fonction de la régularité de f .Voici les deux exemples les plus importants.1. Fonctions en escalier . Sur chaque intervalle [t j , t j+1 ], on approche f par une constante, par exemple f (t j ); ici n = 0. Grâce à la continuité uniforme de f sur [a , b ], on montre aussitôt que les fonctions en escalier ainsi obtenues convergent uniformément vers f sur [a , b ].
on peut alors développer un calcul symbolique sur ces opérateurs et l’opérateur de dérivation D. Ainsi, la formule de Taylor traduit la formule symbolique Th = exph D. Ce calcul, ébauché par Leibniz, a été systématisé par Lagrange et Laplace ; à la fin du XIXe siècle, il a été repris dans le cadre général de la théorie des opérateurs de convolution, c’est-à-dire des opérateurs qui commutent aux translations.GénéralisationsLe problème de l’interpolation se pose aussi pour les fonctions périodiques, auquel cas les fonctions polynomiales sont remplacées par des polynômes trigonométriques. Ces deux exemples se placent dans la théorie générale des systèmes de Tchebychev : on se donne un sous-espace En de dimension n + 1 de l’espace 暈([ 見, 廓]) qui est régulier , c’est-à-dire tel que tout élément de En qui s’annule en au moins n + 1 points est nul. Étant donné une base 﨏0, 﨏1, ..., 﨏n de En , on interpole f par une combinaison linéaire de ces fonctions. On peut montrer, en particulier, que l’espace vectoriel des solutions d’une équation différentielle linéaire sans second membre d’ordre n + 1 est régulier.Interpolation polynomiale par morceauxThéorie classiqueOn considère cette fois une fonction f continue sur un intervalle [a , b ], que l’on découpe en p intervalles [t j , t j+1 ] de longueur (b 漣 a )/p et, sur chacun de ces intervalles, on effectue une interpolation de Lagrange ou de Hermite de f , par des polynômes de degré 諒 n . En pratique, n est fixé et assez petit pour éviter les phénomènes du type de Runge. Il s’agit alors d’étudier la convergence de la suite ( 﨏p ) des fonctions polynomiales par morceaux ainsi obtenues vers la fonction f et la rapidité de convergence en fonction de la régularité de f .Voici les deux exemples les plus importants.1. Fonctions en escalier . Sur chaque intervalle [t j , t j+1 ], on approche f par une constante, par exemple f (t j ); ici n = 0. Grâce à la continuité uniforme de f sur [a , b ], on montre aussitôt que les fonctions en escalier ainsi obtenues convergent uniformément vers f sur [a , b ].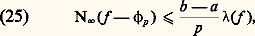 2. Fonctions affines par morceaux . Sur chaque intervalle [t j , t j+1 ], on effectue une interpolation linéaire de f . On montre encore que les fonctions affines par morceaux 﨏p ainsi obtenues convergent uniformément vers f sur [a , b ]. En outre, si f est lipschitzienne de rapport k sur [a , b ], on a:
2. Fonctions affines par morceaux . Sur chaque intervalle [t j , t j+1 ], on effectue une interpolation linéaire de f . On montre encore que les fonctions affines par morceaux 﨏p ainsi obtenues convergent uniformément vers f sur [a , b ]. En outre, si f est lipschitzienne de rapport k sur [a , b ], on a: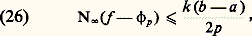 Mais, cette fois, si f est de classe C1, la rapidité de convergence est meilleure. Par exemple, si f est lipschitzienne,
Mais, cette fois, si f est de classe C1, la rapidité de convergence est meilleure. Par exemple, si f est lipschitzienne,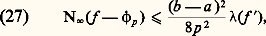 Dans certains problèmes, comme le calcul approché des intégrales (cf. analyse NUMÉRIQUE, chap. 2), on est amené à interpoler f par des fonctions polynomiales par morceaux de degré n plus élevé. Lorsque f est de classe Cn+1 , on a alors:
Dans certains problèmes, comme le calcul approché des intégrales (cf. analyse NUMÉRIQUE, chap. 2), on est amené à interpoler f par des fonctions polynomiales par morceaux de degré n plus élevé. Lorsque f est de classe Cn+1 , on a alors: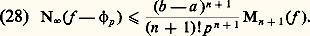 On constate ainsi que la rapidité de convergence est gouvernée par la régularité de f .Fonctions splineLorsque n 閭 2, le procédé précédent présente de nombreux inconvénients, car on approche des fonctions régulières f par des fonctions qui ne sont même pas de classe C1. Il est donc intéressant d’approcher f par des fonctions 﨏 satisfaisant aux deux conditions suivantes:De telles fonctions sont appelées spline (tringle souple). L’espace vectoriel Sn ([a , b ]) de ces fonctions est de dimension n + p . Si on impose maintenant les p + 1 conditions interpolatoires relatives à la fonction f :il reste n 漣 1 paramètres encore libres.Le cas n = 2 (fonctions paraboliques par morceaux) ne conduit pas à une théorie intéressante car il ne reste qu’un seul paramètre, ce qui ne permet pas d’imposer une condition de contact aux deux extrémités de l’intervalle [a , b ]. Au contraire, le cas n = 3 (fonctions spline cubiques) convient bien car il permet d’imposer la condition:Les fonctions spline cubiques conviennent aussi pour l’interpolation des fonctions périodiques. Dans ce cas, on impose à 﨏 de se prolonger en une fonction périodique de classe C2 sur R, ce qui conduit à remplacer la condition (d ) par:d ) D+ 﨏(a ) = D- 﨏(b ) et D2+ 﨏(a ) = D2- 﨏(b ), en désignant par D+ et D- les opérateurs de dérivation à droite et à gauche.On démontre que les conditions a , b , c , d ou (d ), déterminent 﨏 de manière unique. Cette fonction se note Sp (f ) et s’appelle fonction spline cubique interpolant f à l’ordre p . Il faut cependant remarquer que le calcul explicite de 﨏 nécessite la résolution d’un système d’équations linéaires assez compliqué. En revanche, la qualité de l’approximation est excellente:– si f est de classe C1, on a:
On constate ainsi que la rapidité de convergence est gouvernée par la régularité de f .Fonctions splineLorsque n 閭 2, le procédé précédent présente de nombreux inconvénients, car on approche des fonctions régulières f par des fonctions qui ne sont même pas de classe C1. Il est donc intéressant d’approcher f par des fonctions 﨏 satisfaisant aux deux conditions suivantes:De telles fonctions sont appelées spline (tringle souple). L’espace vectoriel Sn ([a , b ]) de ces fonctions est de dimension n + p . Si on impose maintenant les p + 1 conditions interpolatoires relatives à la fonction f :il reste n 漣 1 paramètres encore libres.Le cas n = 2 (fonctions paraboliques par morceaux) ne conduit pas à une théorie intéressante car il ne reste qu’un seul paramètre, ce qui ne permet pas d’imposer une condition de contact aux deux extrémités de l’intervalle [a , b ]. Au contraire, le cas n = 3 (fonctions spline cubiques) convient bien car il permet d’imposer la condition:Les fonctions spline cubiques conviennent aussi pour l’interpolation des fonctions périodiques. Dans ce cas, on impose à 﨏 de se prolonger en une fonction périodique de classe C2 sur R, ce qui conduit à remplacer la condition (d ) par:d ) D+ 﨏(a ) = D- 﨏(b ) et D2+ 﨏(a ) = D2- 﨏(b ), en désignant par D+ et D- les opérateurs de dérivation à droite et à gauche.On démontre que les conditions a , b , c , d ou (d ), déterminent 﨏 de manière unique. Cette fonction se note Sp (f ) et s’appelle fonction spline cubique interpolant f à l’ordre p . Il faut cependant remarquer que le calcul explicite de 﨏 nécessite la résolution d’un système d’équations linéaires assez compliqué. En revanche, la qualité de l’approximation est excellente:– si f est de classe C1, on a: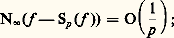 – si f est de classe C2:
– si f est de classe C2: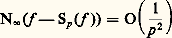 et, en outre:
et, en outre: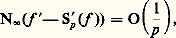 ce qui signifie qu’il y a aussi convergence uniforme pour la dérivée;
ce qui signifie qu’il y a aussi convergence uniforme pour la dérivée;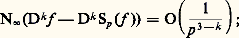
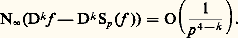 Cependant, si f est de classe C 秊, ou même polynomiale de degré 閭 4 , on ne peut pas améliorer la dernière estimation.Un autre pôle d’intérêt des fonctions spline est relatif à leurs propriétés pour la norme quadratique. Plus précisément, si f est de classe C2, pour tout élément 﨏 de S2,p ([a , b ]), on a:
Cependant, si f est de classe C 秊, ou même polynomiale de degré 閭 4 , on ne peut pas améliorer la dernière estimation.Un autre pôle d’intérêt des fonctions spline est relatif à leurs propriétés pour la norme quadratique. Plus précisément, si f est de classe C2, pour tout élément 﨏 de S2,p ([a , b ]), on a: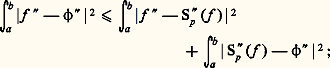 en particulier, parmi toutes les fonctions spline cubiques 﨏, c’est Sp (f ) qui approche le mieux f pour la norme de l’énergie. Cette propriété est à l’origine de la dénomination spline, car on peut montrer, grâce au principe de moindre action, que Sp (f ) réalise la position d’équilibre d’une tringle souple passant par les points interpolateurs et tangente à des droites données aux extrémités de l’intervalle. Ce procédé est depuis longtemps utilisé en dessin industriel. Les fonctions spline se sont révélées très utiles dans les problèmes de conception assistée par ordinateur.La théorie des fonctions spline peut se généraliser aux spline d’ordre impair quelconque. Les propriétés d’approximation sont alors meilleures mais les calculs sont encore plus complexes que pour n = 3, si bien qu’elles sont peu utilisées en analyse numérique.6. Opérations sur les représentations et les approximationsNous avons déjà vu que l’emploi des représentations pour la résolution des problèmes nécessite de pouvoir opérer sur ces représentations: il s’agit non seulement des opérations algébriques (tomme, produit...) mais aussi des opérations de passage à la limite (limites de suites, sommes de séries, intégration, dérivation). Ces problèmes rentrent dans le schéma général d’interversions de passages à la limite. Nous commencerons par préciser les propriétés stables par passage à la limite uniforme pour les suites de fonctions, ce qui est étroitement lié au cas des séries, puis nous examinerons le cas des représentations intégrales. Nous terminerons par quelques indications sur les autres modes de convergence.Suites de fonctionsLes trois problèmes les plus importants sont les suivants.Problème 1 . Continuité et passage à la limite . Soit (f n ) une suite de fonctions continues sur un espace métrique A à valeurs complexes, convergeant sur A vers une fonction f . La fonction f est-elle continue sur A?La réponse est négative pour la convergence simple, comme le montre l’exemple A = [0, 1] et f (x ) = x n .Théorème 1. Stabilité de la continuité . Si (f n ) converge uniformément vers f sur tout compact de A, alors f est continue sur A.Problème 2. Passage à la limite dans les intégrales . On dispose de deux résultats très importants. Le premier est élémentaire.Théorème 2. Passage à la limite dans les intégrales (cas compact) .Soit (f n ) une suite d’applications continues de [a , b ] dans C qui converge uniformément vers f sur [a , b ]. Alors:
en particulier, parmi toutes les fonctions spline cubiques 﨏, c’est Sp (f ) qui approche le mieux f pour la norme de l’énergie. Cette propriété est à l’origine de la dénomination spline, car on peut montrer, grâce au principe de moindre action, que Sp (f ) réalise la position d’équilibre d’une tringle souple passant par les points interpolateurs et tangente à des droites données aux extrémités de l’intervalle. Ce procédé est depuis longtemps utilisé en dessin industriel. Les fonctions spline se sont révélées très utiles dans les problèmes de conception assistée par ordinateur.La théorie des fonctions spline peut se généraliser aux spline d’ordre impair quelconque. Les propriétés d’approximation sont alors meilleures mais les calculs sont encore plus complexes que pour n = 3, si bien qu’elles sont peu utilisées en analyse numérique.6. Opérations sur les représentations et les approximationsNous avons déjà vu que l’emploi des représentations pour la résolution des problèmes nécessite de pouvoir opérer sur ces représentations: il s’agit non seulement des opérations algébriques (tomme, produit...) mais aussi des opérations de passage à la limite (limites de suites, sommes de séries, intégration, dérivation). Ces problèmes rentrent dans le schéma général d’interversions de passages à la limite. Nous commencerons par préciser les propriétés stables par passage à la limite uniforme pour les suites de fonctions, ce qui est étroitement lié au cas des séries, puis nous examinerons le cas des représentations intégrales. Nous terminerons par quelques indications sur les autres modes de convergence.Suites de fonctionsLes trois problèmes les plus importants sont les suivants.Problème 1 . Continuité et passage à la limite . Soit (f n ) une suite de fonctions continues sur un espace métrique A à valeurs complexes, convergeant sur A vers une fonction f . La fonction f est-elle continue sur A?La réponse est négative pour la convergence simple, comme le montre l’exemple A = [0, 1] et f (x ) = x n .Théorème 1. Stabilité de la continuité . Si (f n ) converge uniformément vers f sur tout compact de A, alors f est continue sur A.Problème 2. Passage à la limite dans les intégrales . On dispose de deux résultats très importants. Le premier est élémentaire.Théorème 2. Passage à la limite dans les intégrales (cas compact) .Soit (f n ) une suite d’applications continues de [a , b ] dans C qui converge uniformément vers f sur [a , b ]. Alors: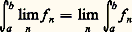 (interversion des signes lim et 咽).Le second résultat a une portée beaucoup plus générale; il se place dans le cadre de la théorie de l’intégrale de Lebesgue [cf. INTÉGRATION ET MESURE].Théorème 2 bis (théorème de convergence dominée) . Soit (f n ) une suite de fonctions à valeurs complexes intégrables sur I et qui converge simplement vers f sur I. On suppose qu’il existe une fonction 﨏 閭 0, intégrable sur I, telle que l’on ait:
(interversion des signes lim et 咽).Le second résultat a une portée beaucoup plus générale; il se place dans le cadre de la théorie de l’intégrale de Lebesgue [cf. INTÉGRATION ET MESURE].Théorème 2 bis (théorème de convergence dominée) . Soit (f n ) une suite de fonctions à valeurs complexes intégrables sur I et qui converge simplement vers f sur I. On suppose qu’il existe une fonction 﨏 閭 0, intégrable sur I, telle que l’on ait: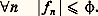 Alors f est intégrable et on a:
Alors f est intégrable et on a: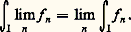 Ce résultat s’étend sans changement au cas où I est une partie localement compacte de Rm .Problème 3. Passage à la limite dans les dérivées . Soit (f n ) une suite de fonctions de classe C1 sur un intervalle I de R, à valeurs complexes, convergeant vers f sur I. La fonction f est-elle de classe C1 sur I et a-t-on Df = limDf n ?L’exemple de I = [0, 1] et f n (x ) = sinnxn montre que la convergence uniforme ne suffit pas. Il faut donc faire des hypothèses sur la suite (Df n ).Théorème 3. Passage à la limite dans les dérivées . On fait les hypothèses suivantes sur la suite (f n ):
Ce résultat s’étend sans changement au cas où I est une partie localement compacte de Rm .Problème 3. Passage à la limite dans les dérivées . Soit (f n ) une suite de fonctions de classe C1 sur un intervalle I de R, à valeurs complexes, convergeant vers f sur I. La fonction f est-elle de classe C1 sur I et a-t-on Df = limDf n ?L’exemple de I = [0, 1] et f n (x ) = sinnxn montre que la convergence uniforme ne suffit pas. Il faut donc faire des hypothèses sur la suite (Df n ).Théorème 3. Passage à la limite dans les dérivées . On fait les hypothèses suivantes sur la suite (f n ):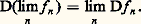 Ce théorème s’étend aussitôt aux fonctions de classe Cp et C 秊 et au cas des fonctions définies sur un ouvert U de Rm .On notera que, en revanche, dans le cas des fonctions analytiques d’une variable complexe, la convergence uniforme sur tout compact de f n vers f entraîne celle de Df n vers Df (théorème de Weierstrass, cf. FONCTIONS ANALYTIQUES -Fonctions d’une variable complexe, chap. 5).Séries de fonctionsOn se donne une série u n de fonctions définies sur un espace métrique A et à valeurs complexes.On dit que cette série converge simplement (resp. uniformément) vers une fonction f si la suite des sommes partielles
Ce théorème s’étend aussitôt aux fonctions de classe Cp et C 秊 et au cas des fonctions définies sur un ouvert U de Rm .On notera que, en revanche, dans le cas des fonctions analytiques d’une variable complexe, la convergence uniforme sur tout compact de f n vers f entraîne celle de Df n vers Df (théorème de Weierstrass, cf. FONCTIONS ANALYTIQUES -Fonctions d’une variable complexe, chap. 5).Séries de fonctionsOn se donne une série u n de fonctions définies sur un espace métrique A et à valeurs complexes.On dit que cette série converge simplement (resp. uniformément) vers une fonction f si la suite des sommes partielles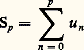 converge simplement (resp. uniformément) vers f .Pour vérifier que la série converge uniformément, on utilise souvent la méthode des séries numériques majorantes. On dit qu’une série numérique 廓n , 廓n 閭 0, est une série majorante sur A de la série de fonctions u n si, pour tout n et pour t 捻 A, on a:
converge simplement (resp. uniformément) vers f .Pour vérifier que la série converge uniformément, on utilise souvent la méthode des séries numériques majorantes. On dit qu’une série numérique 廓n , 廓n 閭 0, est une série majorante sur A de la série de fonctions u n si, pour tout n et pour t 捻 A, on a: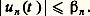 Si la série majorante converge, la convergence de la série u n est uniforme sur A. Dans ces conditions:
Si la série majorante converge, la convergence de la série u n est uniforme sur A. Dans ces conditions: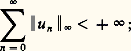 une telle série est dite normalement convergente sur A.En appliquant les théorèmes sur les suites, on obtient les résultats suivants.Théorème 1. Continuité de la somme . Si, pour tout n , la fonction u n est continue sur A et si la série converge uniformément sur tout compact de A vers f , alors f est continue sur A.Théorème 2. Intégration terme à terme sur un intervalle compact . Supposons que, pour tout n , la fonction u n est continue sur [a , b ] et que la série converge uniformément sur [a , b ]. Alors:
une telle série est dite normalement convergente sur A.En appliquant les théorèmes sur les suites, on obtient les résultats suivants.Théorème 1. Continuité de la somme . Si, pour tout n , la fonction u n est continue sur A et si la série converge uniformément sur tout compact de A vers f , alors f est continue sur A.Théorème 2. Intégration terme à terme sur un intervalle compact . Supposons que, pour tout n , la fonction u n est continue sur [a , b ] et que la série converge uniformément sur [a , b ]. Alors: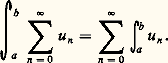 Théorème 2 bis. Intégration terme à terme dans le cas non compact . Soit (u n ) une suite de fonctions à valeurs complexes, intégrables sur I. On suppose:
Théorème 2 bis. Intégration terme à terme dans le cas non compact . Soit (u n ) une suite de fonctions à valeurs complexes, intégrables sur I. On suppose: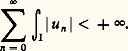
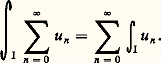 Théorème 3. Dérivation terme à terme . Supposons u n de classe C1 sur I et supposons que les séries u n et Du n convergent uniformément sur tout compact de I. Alors 秊u n est de classe C1 et on a:n = 0
Théorème 3. Dérivation terme à terme . Supposons u n de classe C1 sur I et supposons que les séries u n et Du n convergent uniformément sur tout compact de I. Alors 秊u n est de classe C1 et on a:n = 0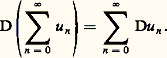 Fonctions définies par des intégralesOn se donne une fonction (x , t ) 料 f (x , t ) définie sur A 憐 I, à valeurs complexes, où A est un espace métrique et I un intervalle de R (ou, plus généralement, une partie localement compacte de Rm ). On veut alors étudier la fonction:
Fonctions définies par des intégralesOn se donne une fonction (x , t ) 料 f (x , t ) définie sur A 憐 I, à valeurs complexes, où A est un espace métrique et I un intervalle de R (ou, plus généralement, une partie localement compacte de Rm ). On veut alors étudier la fonction: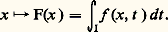 On dispose alors des trois résultats suivants, dont le premier est élémentaire.Théorème 1. Dérivation sous le signe somme (cas des intervalles compacts) . On suppose que A est un intervalle de R et I = [a , b ] un intervalle compact. Alors:b ) si f admet une dérivée partielle 煉f / 煉x continue sur A 憐 [a , b ], alors F est de classe C1 sur A et:
On dispose alors des trois résultats suivants, dont le premier est élémentaire.Théorème 1. Dérivation sous le signe somme (cas des intervalles compacts) . On suppose que A est un intervalle de R et I = [a , b ] un intervalle compact. Alors:b ) si f admet une dérivée partielle 煉f / 煉x continue sur A 憐 [a , b ], alors F est de classe C1 sur A et: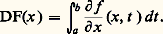 Ce théorème a été utilisé par Leibniz.Théorème 2. Dérivation sous le signe somme (Leibniz-Lebesgue) . Soit A et I des intervalles de R. On fait les hypothèses suivantes:c ) pour tout compact K de A, il existe 﨏K 閭 0, intégrable sur I, telle que:
Ce théorème a été utilisé par Leibniz.Théorème 2. Dérivation sous le signe somme (Leibniz-Lebesgue) . Soit A et I des intervalles de R. On fait les hypothèses suivantes:c ) pour tout compact K de A, il existe 﨏K 閭 0, intégrable sur I, telle que: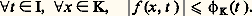 Alors f est continue sur A.Si, de plus, on a:d ) f admet une dérivée partielle 煉f / 煉x continue par rapport à x et satisfait à une hypothèse de domination sur tout compact K de A,alors F est de classe C1 sur A et on a:
Alors f est continue sur A.Si, de plus, on a:d ) f admet une dérivée partielle 煉f / 煉x continue par rapport à x et satisfait à une hypothèse de domination sur tout compact K de A,alors F est de classe C1 sur A et on a: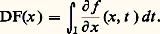 Le problème de l’intégration de F se place dans le cadre plus général de la théorie des intégrales sur un espace produit, où on dispose du théorème suivant, qui permet le calcul d’une telle intégrale par intégrations successives.Théorème de Fubini .1. Soit (x , y ) 料 f (x , y ) une fonction mesurable positive définie sur Rm 憐 Rp . Alors, il est équivalent de dire:a ) f est intégrable sur Rm 憐 Rp ;
Le problème de l’intégration de F se place dans le cadre plus général de la théorie des intégrales sur un espace produit, où on dispose du théorème suivant, qui permet le calcul d’une telle intégrale par intégrations successives.Théorème de Fubini .1. Soit (x , y ) 料 f (x , y ) une fonction mesurable positive définie sur Rm 憐 Rp . Alors, il est équivalent de dire:a ) f est intégrable sur Rm 憐 Rp ;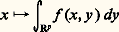 est intégrable sur Rm ;Dans ces conditions, on a alors:
est intégrable sur Rm ;Dans ces conditions, on a alors: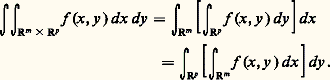 2. Si f est à valeurs complexes, (a ) entraîne (b ) et (b ) et on a la formule de calcul de l’intégrale double; mais ici les conditions (a ), (b ) et (b ) ne sont plus équivalentes, comme le montrent des exemples classiques.Emploi des distributionsLes théorèmes précédents sont satisfaisants en ce qui concerne la continuité et l’intégration mais le sont beaucoup moins en ce qui concerne la dérivation. Cela tient au fait que, dans les espaces classiques de fonctions, l’opérateur D de dérivation n’est pas continu. Un des avantages principaux de la théorie des distributions est précisément de fournir un cadre théorique dans lequel la dérivation est une opération régulière au sens suivant: toute distribution T est indéfiniment dérivable et si une suite (Tn ) de distributions converge vers T, alors (DTn ) converge vers T [cf. DISTRIBUTIONS (mathématiques)].Le seul inconvénient est que la convergence des distributions ne peut pas être décrite par une norme. C’est pourquoi on introduit les espaces de Sobolev : ce sont des sous-espaces de 阮 qui présentent les mêmes avantages que 阮 mais qui, en outre, sont des espaces hilbertiens et sont bien adaptés à l’emploi de la transformation de Fourier et à l’étude des problèmes aux limites des équations aux dérivées partielles (cf. équations aux DÉRIVÉES PARTIELLES – Théorie linéaire).Pour définir ces espaces, on considère l’espace vectoriel 崙 (Rn ) des distributions tempérées sur Rn ; on sait que la transformation de Fourier T 料 T est un automorphisme de 崙 (cf. DISTRIBUTIONS, chap. 4).Pour tout s 捻 R, on introduit le sous-espace vectoriel Hs (Rn ) ees distributions tempérées T telles que:
2. Si f est à valeurs complexes, (a ) entraîne (b ) et (b ) et on a la formule de calcul de l’intégrale double; mais ici les conditions (a ), (b ) et (b ) ne sont plus équivalentes, comme le montrent des exemples classiques.Emploi des distributionsLes théorèmes précédents sont satisfaisants en ce qui concerne la continuité et l’intégration mais le sont beaucoup moins en ce qui concerne la dérivation. Cela tient au fait que, dans les espaces classiques de fonctions, l’opérateur D de dérivation n’est pas continu. Un des avantages principaux de la théorie des distributions est précisément de fournir un cadre théorique dans lequel la dérivation est une opération régulière au sens suivant: toute distribution T est indéfiniment dérivable et si une suite (Tn ) de distributions converge vers T, alors (DTn ) converge vers T [cf. DISTRIBUTIONS (mathématiques)].Le seul inconvénient est que la convergence des distributions ne peut pas être décrite par une norme. C’est pourquoi on introduit les espaces de Sobolev : ce sont des sous-espaces de 阮 qui présentent les mêmes avantages que 阮 mais qui, en outre, sont des espaces hilbertiens et sont bien adaptés à l’emploi de la transformation de Fourier et à l’étude des problèmes aux limites des équations aux dérivées partielles (cf. équations aux DÉRIVÉES PARTIELLES – Théorie linéaire).Pour définir ces espaces, on considère l’espace vectoriel 崙 (Rn ) des distributions tempérées sur Rn ; on sait que la transformation de Fourier T 料 T est un automorphisme de 崙 (cf. DISTRIBUTIONS, chap. 4).Pour tout s 捻 R, on introduit le sous-espace vectoriel Hs (Rn ) ees distributions tempérées T telles que: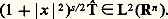 Par l’isomorphisme T 料 (1 + |x |2)s /2T, on transporte à Hs la structure hilbertienne de L2, en posant:
Par l’isomorphisme T 料 (1 + |x |2)s /2T, on transporte à Hs la structure hilbertienne de L2, en posant: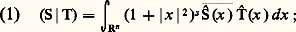 l’opérateur de dérivation:
l’opérateur de dérivation: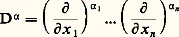 est alors une application continue de Hs dans Hs size=1漣| size=1見|, où | 見| = 見1 + ... + 見n .Lorsque s = 0, on a H0(Rn ) = L2(Rn ). Plus généralement, pour s = p 捻 N, Hp (Rn ) n’est autre que l’espace des distributions T telles que D size=1見T 捻 L2(Rn ) pour tout 見 vérifiant | 見| 諒 p ; en outre, le produit scalaire (1) est alors équivalent au suivant:
est alors une application continue de Hs dans Hs size=1漣| size=1見|, où | 見| = 見1 + ... + 見n .Lorsque s = 0, on a H0(Rn ) = L2(Rn ). Plus généralement, pour s = p 捻 N, Hp (Rn ) n’est autre que l’espace des distributions T telles que D size=1見T 捻 L2(Rn ) pour tout 見 vérifiant | 見| 諒 p ; en outre, le produit scalaire (1) est alors équivalent au suivant: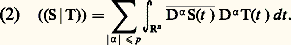
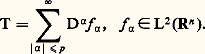 En outre, on peut repasser de la théorie Hs à la théorie classique Ck grâce au théorème suivant.Théorème de Sobolev . Si k 捻 N et si s 閭 n 2 + k , alors Ns (Rn ) 說 Ck (Rn ) et, si f n0 dans Hs , alors D size=1見見f n0 uniformément sur tout compact de Rn pour tout multi-indice 見 tel que | 見| 諒 k .Soit enfin K un compact de Rn et Hs K le sous-espace vectoriel fermé de Hs constitué des distributions à support contenu dans K. On dispose alors du théorème de Rellich.Théorème de Rellich . Si s 礪 t , alors Hs K 說 Ht K et, de toute suite bornée de Hs , on peut extraire une sous-suite convergente dans Ht .Une autre interprétation des espaces Hs est fournie par le théorème suivant.Théorème . Soit s 閭 0 écrit sous la forme s = p + 靖, où 0 諒 靖 麗 1. Alors f 捻 Hs (Rn ) si et seulement si D size=1見f 捻 L2(Rn ) pour | 見| 諒 p et:
En outre, on peut repasser de la théorie Hs à la théorie classique Ck grâce au théorème suivant.Théorème de Sobolev . Si k 捻 N et si s 閭 n 2 + k , alors Ns (Rn ) 說 Ck (Rn ) et, si f n0 dans Hs , alors D size=1見見f n0 uniformément sur tout compact de Rn pour tout multi-indice 見 tel que | 見| 諒 k .Soit enfin K un compact de Rn et Hs K le sous-espace vectoriel fermé de Hs constitué des distributions à support contenu dans K. On dispose alors du théorème de Rellich.Théorème de Rellich . Si s 礪 t , alors Hs K 說 Ht K et, de toute suite bornée de Hs , on peut extraire une sous-suite convergente dans Ht .Une autre interprétation des espaces Hs est fournie par le théorème suivant.Théorème . Soit s 閭 0 écrit sous la forme s = p + 靖, où 0 諒 靖 麗 1. Alors f 捻 Hs (Rn ) si et seulement si D size=1見f 捻 L2(Rn ) pour | 見| 諒 p et: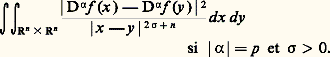 Ce théorème permet notamment de prouver l’invariance de Hs par difféomorphisme et de définir l’espace Hs ( ) pour toute sous-variété C 秊 de dimension n .Dans la théorie des équations aux dérivées partielles, on a besoin des espaces de Sobolev relatifs à un ouvert U borné de Rn dont la frontière X est une variété compacte de classe C 秊. On définit alors Hs (U 漣) comme l’ensemble des restrictions à U des éléments de Hs (Rn ).Les résultats concernant Hp et H-p s’étendent à ce cas ainsi que le théorème de Rellich, où K est remplacé par U 漣. En outre, si s 礪 1/2, l’application f 料 f |X, définie sur 阮(Rn ), se prolonge de manière unique en une application linéaire continue de Hs (U 漣) dans Hs size=1漣1/2(X), appelée trace sur X et notée T|X. Ces notions permettent de poser les problèmes aux limites de la théorie des équations aux dérivées partielles dans le cadre de la théorie des distributions (cf. équations aux DÉRIVÉES PARTIELLES – Théorie linéaire).7. Stabilité et consistanceOn peut décrire les procédés linéaires d’approximation par le schéma général suivant: soit E et F des espaces vectoriels normés de fonctions, et u une application linéaire continue de E dans F. Un processus linéaire d’approximation de u est une suite (u n ) d’applications linéaires continues de E dans F telles que, pour tout élément f de E, u n (f ) converge vers u (f ).Le cas le plus classique est celui où F = E et où u est l’application identique de E, c’est-à-dire où u n (f ) converge vers f ; nous en avons fourni de nombreux exemples aux chapitres 4 et 5, les plus significatifs étant ceux des séries de Fourier et de l’interpolation de Lagrange. Le cas où F = C, c’est-à-dire où u est une forme linéaire sur E est aussi très intéressant (cf. analyse NUMÉRIQUE).StabilitéUn des problèmes les plus importants, surtout pour l’analyse numérique, concerne la stabilité du processus (u n ): si l’on fait une petite erreur sur la fonction f , c’est-à-dire si on remplace f par une fonction g proche de f dans E, u n (g ) converge-t-elle vers un élément proche de u (f )? La réponse est fournie par le résultat suivant.Théorème 1. Caractérisation des processus stables.1. Si la suite (face=F0019 瑩u n 瑩) des normes des applications linéaires u n est bornée par un nombre M indépendant de n , alors, pour tout couple (f , g ) d’éléments de E:
Ce théorème permet notamment de prouver l’invariance de Hs par difféomorphisme et de définir l’espace Hs ( ) pour toute sous-variété C 秊 de dimension n .Dans la théorie des équations aux dérivées partielles, on a besoin des espaces de Sobolev relatifs à un ouvert U borné de Rn dont la frontière X est une variété compacte de classe C 秊. On définit alors Hs (U 漣) comme l’ensemble des restrictions à U des éléments de Hs (Rn ).Les résultats concernant Hp et H-p s’étendent à ce cas ainsi que le théorème de Rellich, où K est remplacé par U 漣. En outre, si s 礪 1/2, l’application f 料 f |X, définie sur 阮(Rn ), se prolonge de manière unique en une application linéaire continue de Hs (U 漣) dans Hs size=1漣1/2(X), appelée trace sur X et notée T|X. Ces notions permettent de poser les problèmes aux limites de la théorie des équations aux dérivées partielles dans le cadre de la théorie des distributions (cf. équations aux DÉRIVÉES PARTIELLES – Théorie linéaire).7. Stabilité et consistanceOn peut décrire les procédés linéaires d’approximation par le schéma général suivant: soit E et F des espaces vectoriels normés de fonctions, et u une application linéaire continue de E dans F. Un processus linéaire d’approximation de u est une suite (u n ) d’applications linéaires continues de E dans F telles que, pour tout élément f de E, u n (f ) converge vers u (f ).Le cas le plus classique est celui où F = E et où u est l’application identique de E, c’est-à-dire où u n (f ) converge vers f ; nous en avons fourni de nombreux exemples aux chapitres 4 et 5, les plus significatifs étant ceux des séries de Fourier et de l’interpolation de Lagrange. Le cas où F = C, c’est-à-dire où u est une forme linéaire sur E est aussi très intéressant (cf. analyse NUMÉRIQUE).StabilitéUn des problèmes les plus importants, surtout pour l’analyse numérique, concerne la stabilité du processus (u n ): si l’on fait une petite erreur sur la fonction f , c’est-à-dire si on remplace f par une fonction g proche de f dans E, u n (g ) converge-t-elle vers un élément proche de u (f )? La réponse est fournie par le résultat suivant.Théorème 1. Caractérisation des processus stables.1. Si la suite (face=F0019 瑩u n 瑩) des normes des applications linéaires u n est bornée par un nombre M indépendant de n , alors, pour tout couple (f , g ) d’éléments de E: 2. Réciproquement, si (face=F0019 瑩u n 瑩) n’est pas bornée, alors, pour tout élément f de E, il existe une suite (g n ) d’éléments de E qui converge vers f et telle que 瑩u n (g n ) 漣 u (f ) 瑩+ 秊.C’est pourquoi, on dit que le processus (u n ) est stable dans le cas (1) et instable dans le cas (2).En fait, ce résultat n’est pertinent que si les espaces normés E et F sont complets, car, si E n’est pas complet, E est un sous-espace dense d’un espace normé plus gros, à savoir son complété Ê; si bien que, en faisant une erreur sur f , on risque de passer à un élément g de Ê qui n’appartient pas à E. C’est le cas où, par exemple, Ê = 暈([a , b ]) muni de la norme de la convergence uniforme et si E = Cp ([a , b ]). D’où l’intérêt du résultat suivant.Théorème 1 . Stabilité et passage à un sous-espace vectoriel dense. Soit Ê et F des espaces de Banach et E un sous-espace dense de Ê. On considère une suite (u n ) d’applications linéaires continues de E dans F satisfaisant aux deux conditions suivantes:Alors u est linéaire continue sur E, 瑩u 瑩 諒 M, et les applications u n et u se prolongent de manière unique en des applications linéaires continues de Ê dans F, qui satisfont aux conditions (a ) et (b ) sur Ê. Ainsi, le processus (u n ) est stable, non seulement sur E mais sur Ê.Dans le cas où E est complet , il est tout à fait remarquable que la convergence implique la stabilité.Théorème 2 (stabilité et complétude) . Soit E et F des espaces de Banach, (u n ) une suite d’applications linéaires continues de E dans F telle que, pour tout x de E, la suite (u n (x )) converge dans F vers u (x ). Alors:a ) il existe M tel que 瑩u n 瑩 諒 M;b ) u est linéaire continue;C’est le théorème de Banach-Steinhaus (cf. espaces vectoriels NORMÉS, chap. 4).Le cas des séries de Fourier est à cet égard exemplaire; c’est d’ailleurs un des exemples qui a été historiquement à l’origine du théorème général précédent. Ici E est l’espace vectoriel 暈(T) des fonctions continues 1-périodiques muni de la norme N size=1秊; cet espace est complet; u n est la forme linéaire qui, à tout élément f de 暈(T), associe la valeur de la somme partielle s n (f ) de sa série de Fourier en un point donné x ; u n (f ) n’est autre que Dn f (x ), où Dn est le noyau de Dirichlet.On montre que:
2. Réciproquement, si (face=F0019 瑩u n 瑩) n’est pas bornée, alors, pour tout élément f de E, il existe une suite (g n ) d’éléments de E qui converge vers f et telle que 瑩u n (g n ) 漣 u (f ) 瑩+ 秊.C’est pourquoi, on dit que le processus (u n ) est stable dans le cas (1) et instable dans le cas (2).En fait, ce résultat n’est pertinent que si les espaces normés E et F sont complets, car, si E n’est pas complet, E est un sous-espace dense d’un espace normé plus gros, à savoir son complété Ê; si bien que, en faisant une erreur sur f , on risque de passer à un élément g de Ê qui n’appartient pas à E. C’est le cas où, par exemple, Ê = 暈([a , b ]) muni de la norme de la convergence uniforme et si E = Cp ([a , b ]). D’où l’intérêt du résultat suivant.Théorème 1 . Stabilité et passage à un sous-espace vectoriel dense. Soit Ê et F des espaces de Banach et E un sous-espace dense de Ê. On considère une suite (u n ) d’applications linéaires continues de E dans F satisfaisant aux deux conditions suivantes:Alors u est linéaire continue sur E, 瑩u 瑩 諒 M, et les applications u n et u se prolongent de manière unique en des applications linéaires continues de Ê dans F, qui satisfont aux conditions (a ) et (b ) sur Ê. Ainsi, le processus (u n ) est stable, non seulement sur E mais sur Ê.Dans le cas où E est complet , il est tout à fait remarquable que la convergence implique la stabilité.Théorème 2 (stabilité et complétude) . Soit E et F des espaces de Banach, (u n ) une suite d’applications linéaires continues de E dans F telle que, pour tout x de E, la suite (u n (x )) converge dans F vers u (x ). Alors:a ) il existe M tel que 瑩u n 瑩 諒 M;b ) u est linéaire continue;C’est le théorème de Banach-Steinhaus (cf. espaces vectoriels NORMÉS, chap. 4).Le cas des séries de Fourier est à cet égard exemplaire; c’est d’ailleurs un des exemples qui a été historiquement à l’origine du théorème général précédent. Ici E est l’espace vectoriel 暈(T) des fonctions continues 1-périodiques muni de la norme N size=1秊; cet espace est complet; u n est la forme linéaire qui, à tout élément f de 暈(T), associe la valeur de la somme partielle s n (f ) de sa série de Fourier en un point donné x ; u n (f ) n’est autre que Dn f (x ), où Dn est le noyau de Dirichlet.On montre que: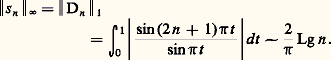 Ainsi, 瑩Dn 瑩1 n’est pas borné; il existe donc des fonctions continues dont la série de Fourier diverge au point x . Cependant, la convergence uniforme de s n (f ) vers f est assurée par exemple si f appartient au sous-ensemble dense des fonctions périodiques de classe C1 (cf. séries TRIGONOMÉTRIQUES).Comme nous l’avons déjà vu au chapitre 5, un phénomène analogue se produit pour les processus interpolatoires.En revanche, le processus d’approximation par les sommes partielles s n (f ) est stable sur (face=F0021 暈(T), N2), et même sur (L2(T), N2) car ici s n est un projecteur orthogonal et 瑩s n 瑩2 = 1. De même, si on prend les sommes de Fejer 靖n (f ) = Fn f , alors 瑩 靖n 瑩 size=1秊 = 1, ce qui assure la stabilité sur (face=F0021 暈(T), N size=1秊).On observera que, dans ce dernier cas, le noyau est positif. Cette condition assure la stabilité de manière très générale.Théorème 3. Continuité des opérateurs linéaires positifs . Soit u un endomorphisme de l’espace vectoriel 暈(T), ou 暈([a , b ]), muni de la norme N size=1秊. On suppose u positif , c’est-à-dire u (f ) 閭 0 pour tout f 閭 0. Alors u est continu; plus précisément:
Ainsi, 瑩Dn 瑩1 n’est pas borné; il existe donc des fonctions continues dont la série de Fourier diverge au point x . Cependant, la convergence uniforme de s n (f ) vers f est assurée par exemple si f appartient au sous-ensemble dense des fonctions périodiques de classe C1 (cf. séries TRIGONOMÉTRIQUES).Comme nous l’avons déjà vu au chapitre 5, un phénomène analogue se produit pour les processus interpolatoires.En revanche, le processus d’approximation par les sommes partielles s n (f ) est stable sur (face=F0021 暈(T), N2), et même sur (L2(T), N2) car ici s n est un projecteur orthogonal et 瑩s n 瑩2 = 1. De même, si on prend les sommes de Fejer 靖n (f ) = Fn f , alors 瑩 靖n 瑩 size=1秊 = 1, ce qui assure la stabilité sur (face=F0021 暈(T), N size=1秊).On observera que, dans ce dernier cas, le noyau est positif. Cette condition assure la stabilité de manière très générale.Théorème 3. Continuité des opérateurs linéaires positifs . Soit u un endomorphisme de l’espace vectoriel 暈(T), ou 暈([a , b ]), muni de la norme N size=1秊. On suppose u positif , c’est-à-dire u (f ) 閭 0 pour tout f 閭 0. Alors u est continu; plus précisément: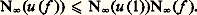 Si maintenant (u n ) est une suite d’opérateurs linéaires positifs qui converge simplement vers un opérateur u , auquel cas u est positif, alors la condition de stabilité est satisfaite pour u n :
Si maintenant (u n ) est une suite d’opérateurs linéaires positifs qui converge simplement vers un opérateur u , auquel cas u est positif, alors la condition de stabilité est satisfaite pour u n :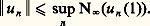 En outre, le théorème suivant assure la convergence du processus sous des hypothèses très faibles.Théorème 4 (théorème de Korovkine). Soit (u n ) une suite d’endomorphismes positifs de 暈([a , b ]) muni de la norme N size=1秊 et u un endomorphisme de cet espace satisfaisant aux conditions suivantes: u n (f )u (f ) uniformément sur [a , b ] pour chacune des trois fonctions x 料 1, x 料 x et x 料 x 2. Alors u n (f )u (f ) pour toute fonction continue f .Ce théorème fournit une nouvelle démonstration, due à Bernstein, du théorème d’approximation polynomiale de Weierstrass.Théorème 5 . On considère les polynômes de Bernstein:
En outre, le théorème suivant assure la convergence du processus sous des hypothèses très faibles.Théorème 4 (théorème de Korovkine). Soit (u n ) une suite d’endomorphismes positifs de 暈([a , b ]) muni de la norme N size=1秊 et u un endomorphisme de cet espace satisfaisant aux conditions suivantes: u n (f )u (f ) uniformément sur [a , b ] pour chacune des trois fonctions x 料 1, x 料 x et x 料 x 2. Alors u n (f )u (f ) pour toute fonction continue f .Ce théorème fournit une nouvelle démonstration, due à Bernstein, du théorème d’approximation polynomiale de Weierstrass.Théorème 5 . On considère les polynômes de Bernstein: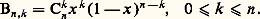
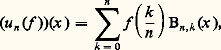 La convergence n’est pas très rapide car, si f est, par exemple, la fonction x 料 x 2, on a 瑩u n (f ) 漣 f 瑩 = 1/4 n .D’ailleurs, l’approximation polynomiale par des opérateurs positifs u n ne peut jamais être rapide, car on démontre que 瑩u n (f ) 漣 f 瑩 size=1秊 n’est pas négligeable devant 1/n 2 pour l’une au moins des trois fonctions x 料 1, x 料 x , x 料 x 2.Enfin, le théorème de Korovkine s’étend aussitôt au cas des fonctions continues périodiques; il suffit que la convergence de u n (f ) vers f soit assurée pour les trois fonctions x 料 1, x 料 cos2 神x , x 料 sin2 神x . On retrouve ainsi la convergence uniforme des sommes de Fejer 靖n (f ) pour toute fonction continue périodique; ici encore la convergence est lente car 瑩 靖n (f ) 漣 f 瑩 size=1秊 est exactement de l’ordre de 1/n lorsque f (x ) = |cos2 神x |.ConsistanceDans de nombreux exemples, le processus d’approximation (u n ) d’une application u de E dans F se présente sous la forme suivante: on se donne une suite (En ) de sous-espaces vectoriels de dimension finie d’un espace vectoriel normé E de fonctions telle que
La convergence n’est pas très rapide car, si f est, par exemple, la fonction x 料 x 2, on a 瑩u n (f ) 漣 f 瑩 = 1/4 n .D’ailleurs, l’approximation polynomiale par des opérateurs positifs u n ne peut jamais être rapide, car on démontre que 瑩u n (f ) 漣 f 瑩 size=1秊 n’est pas négligeable devant 1/n 2 pour l’une au moins des trois fonctions x 料 1, x 料 x , x 料 x 2.Enfin, le théorème de Korovkine s’étend aussitôt au cas des fonctions continues périodiques; il suffit que la convergence de u n (f ) vers f soit assurée pour les trois fonctions x 料 1, x 料 cos2 神x , x 料 sin2 神x . On retrouve ainsi la convergence uniforme des sommes de Fejer 靖n (f ) pour toute fonction continue périodique; ici encore la convergence est lente car 瑩 靖n (f ) 漣 f 瑩 size=1秊 est exactement de l’ordre de 1/n lorsque f (x ) = |cos2 神x |.ConsistanceDans de nombreux exemples, le processus d’approximation (u n ) d’une application u de E dans F se présente sous la forme suivante: on se donne une suite (En ) de sous-espaces vectoriels de dimension finie d’un espace vectoriel normé E de fonctions telle que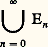 soit dense dans E. On dit alors que le processus (u n ) est consistant si, pour tout élément 﨏 捻 En , u n ( 﨏) = u ( 﨏), c’est-à-dire u n = u sur En .Un cas particulièrement important est celui où u n est défini à partir d’une suite (p n ) de projecteurs de E sur En grâce à la relation u n = u 獵 p n . Si E = F = 暈(T) muni de la norme 2 et si En = 淪n est l’espace vectoriel des polynômes trigonométriques de degré 諒 n , on peut prendre pour p n le projecteur orthogonal de E sur En . Il en est de même si E = F = 暈([a , b ]), muni de la norme:
soit dense dans E. On dit alors que le processus (u n ) est consistant si, pour tout élément 﨏 捻 En , u n ( 﨏) = u ( 﨏), c’est-à-dire u n = u sur En .Un cas particulièrement important est celui où u n est défini à partir d’une suite (p n ) de projecteurs de E sur En grâce à la relation u n = u 獵 p n . Si E = F = 暈(T) muni de la norme 2 et si En = 淪n est l’espace vectoriel des polynômes trigonométriques de degré 諒 n , on peut prendre pour p n le projecteur orthogonal de E sur En . Il en est de même si E = F = 暈([a , b ]), muni de la norme: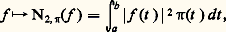 où 神 est un poids , c’est-à-dire une fonction positive intégrable donnée sur [a , b ] et si En = 戮n .Lorsque E = F = 暈([a , b ]) muni de la norme N size=1秊 et En = 戮n , les interpolations de Lagrange ou, plus généralement, d’Hermite constituent aussi des exemples significatifs.Pour étudier la convergence des processus consistants, l’idée est de comparer u n (f ) à un élément 﨏n (f ) approchant f le mieux possible. Plus précisément, on note 嗀n (f ) la distance d’un élément f de E à En , définie par:
où 神 est un poids , c’est-à-dire une fonction positive intégrable donnée sur [a , b ] et si En = 戮n .Lorsque E = F = 暈([a , b ]) muni de la norme N size=1秊 et En = 戮n , les interpolations de Lagrange ou, plus généralement, d’Hermite constituent aussi des exemples significatifs.Pour étudier la convergence des processus consistants, l’idée est de comparer u n (f ) à un élément 﨏n (f ) approchant f le mieux possible. Plus précisément, on note 嗀n (f ) la distance d’un élément f de E à En , définie par: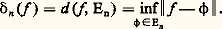 Comme En est de dimension finie, il existe au moins un élément 﨏n 捻 En tel que 瑩f 漣 﨏n 瑩 = d (f , En ); on dit alors que 﨏n optimise l’approximation de f par les éléments de En . L’étude de ce problème est abordée au chapitre 8.
Comme En est de dimension finie, il existe au moins un élément 﨏n 捻 En tel que 瑩f 漣 﨏n 瑩 = d (f , En ); on dit alors que 﨏n optimise l’approximation de f par les éléments de En . L’étude de ce problème est abordée au chapitre 8.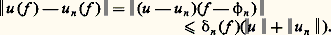 Le problème de la convergence du processus (u n ) et de sa rapidité de convergence est alors séparé en deux questions totalement distinctes:– l’évaluation de 嗀n (f ) qui est liée à la régularité de la fonction que l’on veut approcher;– l’évaluation de 瑩u n 瑩 qui mesure la qualité du processus d’approximation.8. Optimisation de l’approximation; rapidité de convergenceOptimisation de l’approximationAvec les notations du chapitre précédent, nous allons étudier les deux problèmes suivants:a ) l’unicité de l’élément 﨏n de En optimisant l’approximation de f par les éléments de En ; il est alors intéressant de construire des méthodes explicites de calcul de 﨏n ;b ) la distance 嗀n (f ) tend-elle vers 0 si n tend vers + 秊? Si oui, déterminer la vitesse de convergence en fonction des propriétés de f .Voici deux exemples classiques.Dans le premier, E est un espace vectoriel de fonctions 1-périodiques à valeurs complexes et En est le sous-espace vectoriel 淪n des polynômes trigonométriques de degré 諒 n , c’est-à-dire des combinaisons linéaires des fonctions exponentielles t 料 e 2i size=1神pt , où |p | 諒 n .Dans le second, E est un espace vectoriel de fonctions définies sur [a , b ] et En est le sous-espace vectoriel 戮n des polynômes de degré 諒 n .Bien entendu, les réponses aux problèmes précédents vont dépendre du type de convergence considéré. Nous examinerons principalement le cas des normes 2 (approximation en moyenne quadratique) et N size=1秊 (approximation uniforme).Unicité de size=4﨏nThéorème 1 . L’unicité de 﨏n est assurée lorsque la boule unité est strictement convexe , c’est-à-dire si les relations 瑩x 瑩 = 瑩y 瑩 = 1 et 見x + 廓y = 1 avec 見 礪 0, 廓 礪 0, 見 + 廓 = 1 impliquent x = y .Cette dernière condition est réalisée pour l’espace E = L2( 猪) des fonctions de carré intégrable pour une mesure 猪 muni de la norme 2, et, plus généralement, pour les espaces Lp ( 猪) pour 1 麗 p 麗 + 秊. Elle ne l’est pas pour l’espace L1( 猪), ni pour l’espace E = 暈([a , b ]) muni de la norme N size=1秊; on peut relier ce phénomène à la forme des boules de R2 pour ces mêmes normes (cf. figure in espaces vectoriels NORMÉS). D’ailleurs, dans ces deux cas, on peut donner des exemples où il n’y a pas unicité de 﨏n : il suffit par exemple de prendre E = 暈([0, 1]) muni de la norme N size=1秊. Si E0 est la droite vectorielle engendrée par la fonction t 料 t , alors d (1, E0) est atteinte pour toutes les fonctions 﨏(t ) = 見t où 0 諒 見 諒 2. Il en est de même si E est l’espace 暈(T) des fonctions continues 1-périodiques et si E0 est la droite vectorielle engendrée par la fonction t 料 sin2 神t . Cela tient au fait que toutes les fonctions de E0 s’annulent en un même point.Ainsi, le problème de l’unicité de la meilleure approximation uniforme dans E = 暈([a , b ]) est assez délicat. Pour le résoudre, on introduit le concept de sous-espace vectoriel régulier de fonctions (cf. supra , chap. 5).On a alors le théorème suivant, dû à Haar.Théorème 2 . Soit En un sous-espace vectoriel de 暈([a , b ]), ou de l’espace vectoriel 暈(T) des fonctions continues 1-périodiques, muni de la norme de la convergence uniforme. Il est équivalent de dire:a ) En est régulier;Ce théorème s’applique à la meilleure approximation polynomiale uniforme des fonctions continues, car le sous-espace vectoriel des fonctions polynômes de degré 諒 n est régulier. Il s’applique aussi à la meilleure approximation uniforme des fonctions continues périodiques par les polynômes trigonométriques, car le sous-espace vectoriel des polynômes trigonométriques de degré 諒 n est lui aussi régulier.Caractérisation et calcul explicite de size=4﨏nThéorème 3 (cas des normes quadratiques). Soit En un sous-espace vectoriel de dimension finie d’un espace vectoriel hilbertien E. Alors 﨏n n’est autre que la projection orthogonale de f sur En ; autrement dit, 﨏n = p n (f ), où p n est le projecteur orthogonal sur En . En particulier, l’application f 料 﨏n est linéaire continue et:
Le problème de la convergence du processus (u n ) et de sa rapidité de convergence est alors séparé en deux questions totalement distinctes:– l’évaluation de 嗀n (f ) qui est liée à la régularité de la fonction que l’on veut approcher;– l’évaluation de 瑩u n 瑩 qui mesure la qualité du processus d’approximation.8. Optimisation de l’approximation; rapidité de convergenceOptimisation de l’approximationAvec les notations du chapitre précédent, nous allons étudier les deux problèmes suivants:a ) l’unicité de l’élément 﨏n de En optimisant l’approximation de f par les éléments de En ; il est alors intéressant de construire des méthodes explicites de calcul de 﨏n ;b ) la distance 嗀n (f ) tend-elle vers 0 si n tend vers + 秊? Si oui, déterminer la vitesse de convergence en fonction des propriétés de f .Voici deux exemples classiques.Dans le premier, E est un espace vectoriel de fonctions 1-périodiques à valeurs complexes et En est le sous-espace vectoriel 淪n des polynômes trigonométriques de degré 諒 n , c’est-à-dire des combinaisons linéaires des fonctions exponentielles t 料 e 2i size=1神pt , où |p | 諒 n .Dans le second, E est un espace vectoriel de fonctions définies sur [a , b ] et En est le sous-espace vectoriel 戮n des polynômes de degré 諒 n .Bien entendu, les réponses aux problèmes précédents vont dépendre du type de convergence considéré. Nous examinerons principalement le cas des normes 2 (approximation en moyenne quadratique) et N size=1秊 (approximation uniforme).Unicité de size=4﨏nThéorème 1 . L’unicité de 﨏n est assurée lorsque la boule unité est strictement convexe , c’est-à-dire si les relations 瑩x 瑩 = 瑩y 瑩 = 1 et 見x + 廓y = 1 avec 見 礪 0, 廓 礪 0, 見 + 廓 = 1 impliquent x = y .Cette dernière condition est réalisée pour l’espace E = L2( 猪) des fonctions de carré intégrable pour une mesure 猪 muni de la norme 2, et, plus généralement, pour les espaces Lp ( 猪) pour 1 麗 p 麗 + 秊. Elle ne l’est pas pour l’espace L1( 猪), ni pour l’espace E = 暈([a , b ]) muni de la norme N size=1秊; on peut relier ce phénomène à la forme des boules de R2 pour ces mêmes normes (cf. figure in espaces vectoriels NORMÉS). D’ailleurs, dans ces deux cas, on peut donner des exemples où il n’y a pas unicité de 﨏n : il suffit par exemple de prendre E = 暈([0, 1]) muni de la norme N size=1秊. Si E0 est la droite vectorielle engendrée par la fonction t 料 t , alors d (1, E0) est atteinte pour toutes les fonctions 﨏(t ) = 見t où 0 諒 見 諒 2. Il en est de même si E est l’espace 暈(T) des fonctions continues 1-périodiques et si E0 est la droite vectorielle engendrée par la fonction t 料 sin2 神t . Cela tient au fait que toutes les fonctions de E0 s’annulent en un même point.Ainsi, le problème de l’unicité de la meilleure approximation uniforme dans E = 暈([a , b ]) est assez délicat. Pour le résoudre, on introduit le concept de sous-espace vectoriel régulier de fonctions (cf. supra , chap. 5).On a alors le théorème suivant, dû à Haar.Théorème 2 . Soit En un sous-espace vectoriel de 暈([a , b ]), ou de l’espace vectoriel 暈(T) des fonctions continues 1-périodiques, muni de la norme de la convergence uniforme. Il est équivalent de dire:a ) En est régulier;Ce théorème s’applique à la meilleure approximation polynomiale uniforme des fonctions continues, car le sous-espace vectoriel des fonctions polynômes de degré 諒 n est régulier. Il s’applique aussi à la meilleure approximation uniforme des fonctions continues périodiques par les polynômes trigonométriques, car le sous-espace vectoriel des polynômes trigonométriques de degré 諒 n est lui aussi régulier.Caractérisation et calcul explicite de size=4﨏nThéorème 3 (cas des normes quadratiques). Soit En un sous-espace vectoriel de dimension finie d’un espace vectoriel hilbertien E. Alors 﨏n n’est autre que la projection orthogonale de f sur En ; autrement dit, 﨏n = p n (f ), où p n est le projecteur orthogonal sur En . En particulier, l’application f 料 﨏n est linéaire continue et: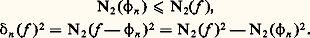 Si on se donne une base (e 0, ..., e n ) de En , on peut calculer explicitement 﨏n . Si cette base est orthonormée, on a:
Si on se donne une base (e 0, ..., e n ) de En , on peut calculer explicitement 﨏n . Si cette base est orthonormée, on a: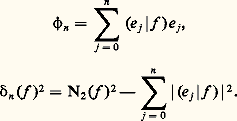 Sinon, les composantes de 﨏n se calculent à l’aide des déterminants de Gram, en particulier:
Sinon, les composantes de 﨏n se calculent à l’aide des déterminants de Gram, en particulier: (cf. espace de HILBERT).Le cas des normes uniformes est plus délicat. Pour simplifier, nous nous limiterons au cas de l’approximation polynomiale uniforme des fonctions continues à valeurs réelles, c’est-à-dire E = 暈([a , b ], R) et En = 戮n , espace des polynômes de degré 諒 n . On dit qu’une suite strictement croissante (t 1, ..., t r ) de points de [a , b ] est alternante pour une fonction F de 暈([a , b ]) si, pour tout j 捻 [1, r ], F(t j ) = N size=1秊(f ) et si, pour tout j 捻 [1, r 漣 1], F(t j )F(t j+1 ) 麗 0; r s’appelle la longueur de la suite. On a alors le théorème suivant.Théorème 4. Théorème d’équioscillation de Tchebychev . Soit f 捻 暈([a , b ]) et 﨏 une fonction polynomiale de degré 諒 n . Il y a équivalence entre:a ) la fonction 﨏 est égale au polynôme de meilleure approximation 﨏n ;Ce théorème détermine 﨏n , mais il n’existe aucun algorithme simple dès que n est un peu grand. C’est néanmoins possible lorsque f est une fonction polynomiale de degré n + 1. Grâce au théorème précédent, on démontre en effet la propriété extrémale des polynômes de Tchebychev, avec ici [a , b ] = [ 漣 1, 1] (cf. supra , chap. 5).Théorème 5 . Soit Tn le polynôme de Tchebychev de degré n ; alors:a ) N size=1秊(Tn ) = 2n-1 et, pour tout polynôme unitaire P de degré n , on a N size=1秊(P) 閭 1/2n-1 , avec égalité si et seulement si P = Tn /2n-1 ;
(cf. espace de HILBERT).Le cas des normes uniformes est plus délicat. Pour simplifier, nous nous limiterons au cas de l’approximation polynomiale uniforme des fonctions continues à valeurs réelles, c’est-à-dire E = 暈([a , b ], R) et En = 戮n , espace des polynômes de degré 諒 n . On dit qu’une suite strictement croissante (t 1, ..., t r ) de points de [a , b ] est alternante pour une fonction F de 暈([a , b ]) si, pour tout j 捻 [1, r ], F(t j ) = N size=1秊(f ) et si, pour tout j 捻 [1, r 漣 1], F(t j )F(t j+1 ) 麗 0; r s’appelle la longueur de la suite. On a alors le théorème suivant.Théorème 4. Théorème d’équioscillation de Tchebychev . Soit f 捻 暈([a , b ]) et 﨏 une fonction polynomiale de degré 諒 n . Il y a équivalence entre:a ) la fonction 﨏 est égale au polynôme de meilleure approximation 﨏n ;Ce théorème détermine 﨏n , mais il n’existe aucun algorithme simple dès que n est un peu grand. C’est néanmoins possible lorsque f est une fonction polynomiale de degré n + 1. Grâce au théorème précédent, on démontre en effet la propriété extrémale des polynômes de Tchebychev, avec ici [a , b ] = [ 漣 1, 1] (cf. supra , chap. 5).Théorème 5 . Soit Tn le polynôme de Tchebychev de degré n ; alors:a ) N size=1秊(Tn ) = 2n-1 et, pour tout polynôme unitaire P de degré n , on a N size=1秊(P) 閭 1/2n-1 , avec égalité si et seulement si P = Tn /2n-1 ;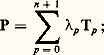 alors:
alors: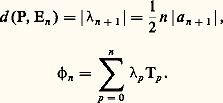 On notera que l’application P 料 﨏n est linéaire, mais, malheureusement, il n’est pas vrai, contrairement au cas des normes 2, que, si P est de degré n + 2, 﨏n s’obtienne en prenant d’abord Q = 﨏n+1 (P) et ensuite 﨏n (Q). Plus généralement, l’application f 料 﨏n n’est pas linéaire. Cependant, en pratique, on utilise souvent une méthode télescopique : on commence par approcher f par un polynôme Pn+p de degré n + p suffisamment élevé pour obtenir la précision cherchée, par exemple en utilisant le développement taylorien de f à l’origine (s’il est connu), puis on développe Pn+p dans la base des polynômes de Tchebychev et on tronque le développement à l’ordre n ; on obtient ainsi un polynôme 祥n , qui n’est pas égal à 﨏n , mais dont on démontre qu’il en diffère fort peu. Une variante de cette méthode dans le cas périodique consiste à développer la fonction x 料 f (cosx ) en série de Fourier:
On notera que l’application P 料 﨏n est linéaire, mais, malheureusement, il n’est pas vrai, contrairement au cas des normes 2, que, si P est de degré n + 2, 﨏n s’obtienne en prenant d’abord Q = 﨏n+1 (P) et ensuite 﨏n (Q). Plus généralement, l’application f 料 﨏n n’est pas linéaire. Cependant, en pratique, on utilise souvent une méthode télescopique : on commence par approcher f par un polynôme Pn+p de degré n + p suffisamment élevé pour obtenir la précision cherchée, par exemple en utilisant le développement taylorien de f à l’origine (s’il est connu), puis on développe Pn+p dans la base des polynômes de Tchebychev et on tronque le développement à l’ordre n ; on obtient ainsi un polynôme 祥n , qui n’est pas égal à 﨏n , mais dont on démontre qu’il en diffère fort peu. Une variante de cette méthode dans le cas périodique consiste à développer la fonction x 料 f (cosx ) en série de Fourier: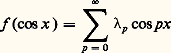 (ce qui revient à développer f en série de polynômes de Tchebychev:
(ce qui revient à développer f en série de polynômes de Tchebychev: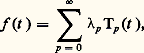 et à effectuer le changement de variable t = cosx ). On calcule les coefficients de Fourierp et le polynôme:
et à effectuer le changement de variable t = cosx ). On calcule les coefficients de Fourierp et le polynôme: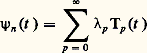 fournit une excellente approximation de f pour un polynôme de degré 麗 n . On peut prouver que le gain par rapport au développement taylorien est de 1/2n , ce qui est en accord avec les résultats du chapitre 5.Convergence de size=4嗀n (f )Il nous reste maintenant à étudier le second problème, qui concerne la convergence vers 0 de 嗀n (f ). Tout d’abord, le théorème d’approximation polynomiale uniforme de Weierstrass signifie que 嗀n (f ) tend vers 0 dans les deux cas classiques E = 暈([a , b ]), En = 戮n et E = 暈(T), En = 淪n pour la norme uniforme N size=1秊.Comme la norme N size=1秊 est plus fine que 2 sur un intervalle compact, le même résultat est valable dans ce cas pour la norme 2 et, par suite, pour les espaces hilbertiens L2([a , b ]) et L2(T).Les résultats explicites fournis par le théorème 3 permettent d’étudier des cas plus fins.Théorème 6 (théorème de Muntz) . Soit E = [0, 1], ( 見n ) une suite strictement croissante de nombres réels positifs telle que 見0 = 0, et En l’espace vectoriel engendré par e size=1見0, ..., e size=1見n , où e size=1廓(t ) = t 廓.1. Si E est muni de la norme 2, il est équivalent de dire:秊b ) la série 1 見n diverge .n = 12. Cette équivalence reste valable si E est muni de la norme N size=1秊.Pour démontrer ce résultat, on calcule la distance de e size=1廓 à En par la méthode de Gramm indiquée plus haut et on montre que cette distance tend vers 0 si et seulement si la condition b est réalisée.La méthode utilisée pour passer de 2 à N size=1秊 consiste en une inégalité du type Sobolev: si f est nulle en 0 et de classe C1, on a:
fournit une excellente approximation de f pour un polynôme de degré 麗 n . On peut prouver que le gain par rapport au développement taylorien est de 1/2n , ce qui est en accord avec les résultats du chapitre 5.Convergence de size=4嗀n (f )Il nous reste maintenant à étudier le second problème, qui concerne la convergence vers 0 de 嗀n (f ). Tout d’abord, le théorème d’approximation polynomiale uniforme de Weierstrass signifie que 嗀n (f ) tend vers 0 dans les deux cas classiques E = 暈([a , b ]), En = 戮n et E = 暈(T), En = 淪n pour la norme uniforme N size=1秊.Comme la norme N size=1秊 est plus fine que 2 sur un intervalle compact, le même résultat est valable dans ce cas pour la norme 2 et, par suite, pour les espaces hilbertiens L2([a , b ]) et L2(T).Les résultats explicites fournis par le théorème 3 permettent d’étudier des cas plus fins.Théorème 6 (théorème de Muntz) . Soit E = [0, 1], ( 見n ) une suite strictement croissante de nombres réels positifs telle que 見0 = 0, et En l’espace vectoriel engendré par e size=1見0, ..., e size=1見n , où e size=1廓(t ) = t 廓.1. Si E est muni de la norme 2, il est équivalent de dire:秊b ) la série 1 見n diverge .n = 12. Cette équivalence reste valable si E est muni de la norme N size=1秊.Pour démontrer ce résultat, on calcule la distance de e size=1廓 à En par la méthode de Gramm indiquée plus haut et on montre que cette distance tend vers 0 si et seulement si la condition b est réalisée.La méthode utilisée pour passer de 2 à N size=1秊 consiste en une inégalité du type Sobolev: si f est nulle en 0 et de classe C1, on a: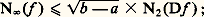 pour approcher uniformément f par des éléments de En , il suffit donc d’approcher Df en moyenne quadratique. Ainsi, le cas de N size=1秊, d’accès difficile par une méthode directe, est résolu grâce à un détour par 2. Ces méthodes sont d’usage constant en analyse fonctionnelle.Enfin, la rapidité de convergence de 嗀n (f ) vers 0 dépend de la régularité de f . Ce phénomène est analogue à celui des séries de Fourier (cf. séries TRIGONOMÉTRIQUES). Pour mesurer de façon précise la régularité des fonctions continues, on introduit le module de continuité . Soit f une fonction continue sur un intervalle I de R; pour tout 嗀 礪 0, on pose:
pour approcher uniformément f par des éléments de En , il suffit donc d’approcher Df en moyenne quadratique. Ainsi, le cas de N size=1秊, d’accès difficile par une méthode directe, est résolu grâce à un détour par 2. Ces méthodes sont d’usage constant en analyse fonctionnelle.Enfin, la rapidité de convergence de 嗀n (f ) vers 0 dépend de la régularité de f . Ce phénomène est analogue à celui des séries de Fourier (cf. séries TRIGONOMÉTRIQUES). Pour mesurer de façon précise la régularité des fonctions continues, on introduit le module de continuité . Soit f une fonction continue sur un intervalle I de R; pour tout 嗀 礪 0, on pose: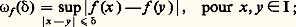 cette notion est très commode car elle permet de décrire différentes classes de fonctions:– la fonction f est uniformément continue sur I si et seulement si 諸f ( 嗀)0 si 嗀0;Plus généralement, f est holdérienne d’ordre 見, pour 0 麗 見 諒 1, si et seulement si 諸f ( 嗀) 諒 k 嗀 size=1見.Dans le cas des normes N size=1秊, on introduit les classes de fonctions suivantes:– l’espace vectoriel Lip size=1見([a , b ]) des fonctions holdériennes sur [a , b ] d’ordre 見, 0 麗 見 諒 1, muni de la norme:
cette notion est très commode car elle permet de décrire différentes classes de fonctions:– la fonction f est uniformément continue sur I si et seulement si 諸f ( 嗀)0 si 嗀0;Plus généralement, f est holdérienne d’ordre 見, pour 0 麗 見 諒 1, si et seulement si 諸f ( 嗀) 諒 k 嗀 size=1見.Dans le cas des normes N size=1秊, on introduit les classes de fonctions suivantes:– l’espace vectoriel Lip size=1見([a , b ]) des fonctions holdériennes sur [a , b ] d’ordre 見, 0 麗 見 諒 1, muni de la norme: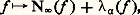 où:
où: Le cas des fonctions périodiques est analogue. Les espaces vectoriels normés Lip size=1見,p sont complets.Pour étudier 嗀n (f ), on commence par le cas des fonctions périodiques et on en déduit le cas 暈([ 漣 1, 1]) par le changement de variable x = cos 神t . Considérons donc une fonction continue 1-périodique f . L’idée est d’approcher f par convolution avec des polynômes trigonométriques 﨑n constituant une approximation de la mesure de Dirac et d’évaluer 瑩f 漣 f 﨑n 瑩 size=1秊.Nous connaissons déjà les noyaux de Dirichlet et de Fejer:
Le cas des fonctions périodiques est analogue. Les espaces vectoriels normés Lip size=1見,p sont complets.Pour étudier 嗀n (f ), on commence par le cas des fonctions périodiques et on en déduit le cas 暈([ 漣 1, 1]) par le changement de variable x = cos 神t . Considérons donc une fonction continue 1-périodique f . L’idée est d’approcher f par convolution avec des polynômes trigonométriques 﨑n constituant une approximation de la mesure de Dirac et d’évaluer 瑩f 漣 f 﨑n 瑩 size=1秊.Nous connaissons déjà les noyaux de Dirichlet et de Fejer: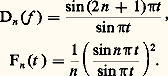 Mais le premier, n’étant pas positif, ne convient pas pour toutes les fonctions continues, et le second, bien que positif, fournit des convergences très lentes, même si f est très régulière. On utilise ici le noyau de Jackson:
Mais le premier, n’étant pas positif, ne convient pas pour toutes les fonctions continues, et le second, bien que positif, fournit des convergences très lentes, même si f est très régulière. On utilise ici le noyau de Jackson: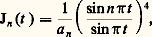 où a n est une constante de normalisation. On a alors le théorème suivant.Théorème 7 (Jackson) . Il existe une constante 廓 礪 0 telle que, pour toute f continue périodique, on ait:
où a n est une constante de normalisation. On a alors le théorème suivant.Théorème 7 (Jackson) . Il existe une constante 廓 礪 0 telle que, pour toute f continue périodique, on ait: En particulier:
En particulier: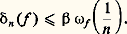 Ainsi, plus f est régulière, plus la décroissance de 嗀n (f ) est rapide. En particulier, si f 捻 Lip size=1見, 嗀n (f ) = O(1/n size=1見).
Ainsi, plus f est régulière, plus la décroissance de 嗀n (f ) est rapide. En particulier, si f 捻 Lip size=1見, 嗀n (f ) = O(1/n size=1見).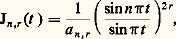 et le théorème 7 se généralise par le théorème suivant.Théorème 7 . Il existe 廓 礪 0 tel que, pour toute fonction périodique de classe Cp , on ait:
et le théorème 7 se généralise par le théorème suivant.Théorème 7 . Il existe 廓 礪 0 tel que, pour toute fonction périodique de classe Cp , on ait: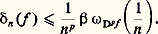 Il est tout à fait remarquable que, inversement, si f est «bien approchée» par les polynômes trigonométriques, c’est-à-dire si 嗀n (f ) tend vers 0 assez rapidement, alors f est assez régulière.
Il est tout à fait remarquable que, inversement, si f est «bien approchée» par les polynômes trigonométriques, c’est-à-dire si 嗀n (f ) tend vers 0 assez rapidement, alors f est assez régulière.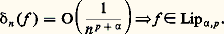 Cela prouve que les estimations fournies par les théorèmes 5 et 5 sont les meilleures possibles. Enfin, si f est C 秊 (resp. holomorphe dans une bande |Imz | 麗 塚), alors 嗀n (f ) est à décroissance rapide (resp. exponentielle); ici encore, les réciproques sont exactes. On notera enfin qu’il existe des fonctions continues f telles que 嗀n (f ) décroisse arbitrairement lentement. Enfin, les théorèmes 5 et 5 s’appliquent sans changement au cas des fonctions continues sur un intervalle [a , b ], mais ici, les réciproques sont plus délicates.Nous ne développerons pas non plus le cas, étudié par Favard et Krein, où 暈([a , b ]) est muni de la norme quadratique; les théorèmes 5 et 5 s’étendent sans changement, les espaces Lip size=1見,p étant remplacés par les espaces de Sobolev H size=1見+p .Convergence des processus d’approximation consistantsNous nous bornerons ici à étudier le cas E = 暈(T), ou E = 暈([a , b ]), où u = IE et où le processus (u n ) d’approximation est défini par une suite de projecteurs p n de E sur En . D’après les résultats du chapitre 7, la convergence de p n (f ) vers un élément f de E est contrôlée par la relation:
Cela prouve que les estimations fournies par les théorèmes 5 et 5 sont les meilleures possibles. Enfin, si f est C 秊 (resp. holomorphe dans une bande |Imz | 麗 塚), alors 嗀n (f ) est à décroissance rapide (resp. exponentielle); ici encore, les réciproques sont exactes. On notera enfin qu’il existe des fonctions continues f telles que 嗀n (f ) décroisse arbitrairement lentement. Enfin, les théorèmes 5 et 5 s’appliquent sans changement au cas des fonctions continues sur un intervalle [a , b ], mais ici, les réciproques sont plus délicates.Nous ne développerons pas non plus le cas, étudié par Favard et Krein, où 暈([a , b ]) est muni de la norme quadratique; les théorèmes 5 et 5 s’étendent sans changement, les espaces Lip size=1見,p étant remplacés par les espaces de Sobolev H size=1見+p .Convergence des processus d’approximation consistantsNous nous bornerons ici à étudier le cas E = 暈(T), ou E = 暈([a , b ]), où u = IE et où le processus (u n ) d’approximation est défini par une suite de projecteurs p n de E sur En . D’après les résultats du chapitre 7, la convergence de p n (f ) vers un élément f de E est contrôlée par la relation: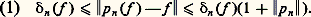 Ayant étudié précédemment la rapidité de convergence vers 0 de 嗀n (f ), il nous reste à examiner le comportement de 瑩p n 瑩. Voici tout d’abord un cas idéal.Théorème 1. Processus consistants et stables . Tout processus à la fois consistant et stable est convergent sur E tout entier car, dans ces conditions, 嗀n (f )0 et 瑩u n 瑩 諒 M. En outre, la vitesse de convergence est de même ordre de grandeur que celle du processus optimal.Nous examinerons maintenant d’abord la possibilité d’obtention de processus d’approximation polynomiale à la fois stables et consistants. Ici encore, la situation est radicalement différente suivant qu’il s’agit d’approximation en moyenne quadratique ou d’approximation uniforme.Approximation polynomiale quadratiqueThéorème 2 . Stabilité et convergence de l’approximation polynomiale en moyenne quadratique.1. Cas des fonctions périodiques . E est l’espace vectoriel L2(T) des fonctions de carré intégrable 1-périodiques muni de la norme 2, En = 淪n est le sous-espace vectoriel des polynômes trigonométriques de degré 諒 n et p n est le projecteur orthogonal de E sur En qui, à toute fonction f , associe la somme partielle s n (f ) de sa série de Fourier.2. Cas des fonctions définies sur un intervalle I de R. On se donne un poids 神 défini sur I, et E est l’espace vectoriel L2(I, 神) des fonctions de carré intégrable pour la mesure de densité 神 muni de la norme 2, size=1神; En = 戮n , sous-espace vectoriel des polynômes de degré 諒 n et p n est le projecteur de E sur En qui associe à f la somme partielle s n (f ) de son développement suivant le système de polynômes orthogonaux défini par 神 (cf. polynômes ORTHOGONAUX).Dans les deux cas, 瑩p n 瑩 = 1, donc le processus est à la fois stable et consistant; nous avons vu précédemment qu’il est d’ailleurs optimal. En particulier, la convergence a lieu pour tout élément f de E et elle est d’autant plus rapide que f est régulière : Il existe 廓 礪 0 tel que:
Ayant étudié précédemment la rapidité de convergence vers 0 de 嗀n (f ), il nous reste à examiner le comportement de 瑩p n 瑩. Voici tout d’abord un cas idéal.Théorème 1. Processus consistants et stables . Tout processus à la fois consistant et stable est convergent sur E tout entier car, dans ces conditions, 嗀n (f )0 et 瑩u n 瑩 諒 M. En outre, la vitesse de convergence est de même ordre de grandeur que celle du processus optimal.Nous examinerons maintenant d’abord la possibilité d’obtention de processus d’approximation polynomiale à la fois stables et consistants. Ici encore, la situation est radicalement différente suivant qu’il s’agit d’approximation en moyenne quadratique ou d’approximation uniforme.Approximation polynomiale quadratiqueThéorème 2 . Stabilité et convergence de l’approximation polynomiale en moyenne quadratique.1. Cas des fonctions périodiques . E est l’espace vectoriel L2(T) des fonctions de carré intégrable 1-périodiques muni de la norme 2, En = 淪n est le sous-espace vectoriel des polynômes trigonométriques de degré 諒 n et p n est le projecteur orthogonal de E sur En qui, à toute fonction f , associe la somme partielle s n (f ) de sa série de Fourier.2. Cas des fonctions définies sur un intervalle I de R. On se donne un poids 神 défini sur I, et E est l’espace vectoriel L2(I, 神) des fonctions de carré intégrable pour la mesure de densité 神 muni de la norme 2, size=1神; En = 戮n , sous-espace vectoriel des polynômes de degré 諒 n et p n est le projecteur de E sur En qui associe à f la somme partielle s n (f ) de son développement suivant le système de polynômes orthogonaux défini par 神 (cf. polynômes ORTHOGONAUX).Dans les deux cas, 瑩p n 瑩 = 1, donc le processus est à la fois stable et consistant; nous avons vu précédemment qu’il est d’ailleurs optimal. En particulier, la convergence a lieu pour tout élément f de E et elle est d’autant plus rapide que f est régulière : Il existe 廓 礪 0 tel que: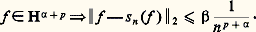 Approximation polynomiale uniformeThéorème 3 (théorème de Bernstein-Faber) . Convergence de l’approximation polynomiale trigonométrique uniforme . On prend E = 暈(T) muni de la norme N size=1秊 et En = 淪n .1. Le processus de Fourier n’est pas stable, car la norme du projecteur p n : f 料 s n (f ) est égale à 瑩Dn 瑩1, où Dn est le noyau de Dirichlet, et 瑩Dn 瑩1 黎 2 神Lgn . Cependant, la convergence uniforme de s n (f ) vers f a bien lieu dès que le module de continuité 諸f (1/n ) est négligeable devant 1/Lg n , et, en particulier, si f est holdérienne d’ordre 見. En outre, la perte de rapidité par rapport au processus optimal est faible, puisque:
Approximation polynomiale uniformeThéorème 3 (théorème de Bernstein-Faber) . Convergence de l’approximation polynomiale trigonométrique uniforme . On prend E = 暈(T) muni de la norme N size=1秊 et En = 淪n .1. Le processus de Fourier n’est pas stable, car la norme du projecteur p n : f 料 s n (f ) est égale à 瑩Dn 瑩1, où Dn est le noyau de Dirichlet, et 瑩Dn 瑩1 黎 2 神Lgn . Cependant, la convergence uniforme de s n (f ) vers f a bien lieu dès que le module de continuité 諸f (1/n ) est négligeable devant 1/Lg n , et, en particulier, si f est holdérienne d’ordre 見. En outre, la perte de rapidité par rapport au processus optimal est faible, puisque: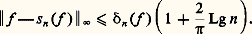
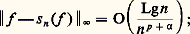 ainsi, la convergence est d’autant plus rapide que f est régulière.2. Le processus de Fourier est optimal parmi les processus consistants . On peut en effet démontrer que, pour tout projecteur continu p n de E = 暈(T) sur 淪n , on a 瑩p n 瑩 閭 瑩Dn 瑩1.3. En particulier, le processus consistant (p n ) n’est jamais stable, et, comme (E, N size=1秊) est complet, il existe des fonctions continues f telles que 瑩p n (f ) 瑩 size=1秊 soit non borné; bien entendu, pour une telle fonction f , la suite p n (f ) ne tend pas vers f .Ainsi, il n’existe pas de processus d’approximation polynomiale trigonométrique à la fois consistant et uniforme, ou, ce qui revient au même, convergent sur tout 暈(T). A fortiori, il n’existe pas de processus consistant positif, ce qui résulte aussi de la méthode de Korovkine.Par changement de variable, on obtient le théorème suivant.Théorème 3 . Convergence de l’approximation polynomiale uniforme.1. Le processus de développement de f en série de polynômes de Tchebychev n’est pas stable, car 瑩p n 瑩 黎 1/Lgn . Mais il converge pour les fonctions telles que 諸f (1/n ) soit négligeable devant 1/Lgn , et d’autant plus rapidement que f est plus régulière.2. Ce processus est optimal parmi les processus consistants.3. En particulier, il n’existe pas de procédé d’approximation polynomiale uniforme à la fois consistant et stable. On notera que (face=F0021 暈([a , b ]), N size=1秊) étant complet, la convergence simple n’est même pas assurée.En outre, pour les fonctions suffisamment régulières, on peut remonter de l’approximation en moyenne quadratique à l’approximation uniforme. Il suffit pour cela de prouver que la série 見n (f )e n donnant le développement de f converge normalement sur l’intervalle considéré. En effet, dans ces conditions, s n (f ) converge uniformément vers une fonction continue g ; comme la convergence uniforme implique la convergence en moyenne quadratique sur un intervalle compact, s n (f ) converge aussi vers g en moyenne quadratique, et, par unicité de la limite, g = f . Pour établir la convergence normale, on majore 瑩e n 瑩 size=1秊 et on utilise le fait que, plus f est régulière, plus la suite ( 見n (f )) décroît rapidement.Le cas des séries de Fourier est bien classique: si f est continue et de classe C1 par morceaux, la série:
ainsi, la convergence est d’autant plus rapide que f est régulière.2. Le processus de Fourier est optimal parmi les processus consistants . On peut en effet démontrer que, pour tout projecteur continu p n de E = 暈(T) sur 淪n , on a 瑩p n 瑩 閭 瑩Dn 瑩1.3. En particulier, le processus consistant (p n ) n’est jamais stable, et, comme (E, N size=1秊) est complet, il existe des fonctions continues f telles que 瑩p n (f ) 瑩 size=1秊 soit non borné; bien entendu, pour une telle fonction f , la suite p n (f ) ne tend pas vers f .Ainsi, il n’existe pas de processus d’approximation polynomiale trigonométrique à la fois consistant et uniforme, ou, ce qui revient au même, convergent sur tout 暈(T). A fortiori, il n’existe pas de processus consistant positif, ce qui résulte aussi de la méthode de Korovkine.Par changement de variable, on obtient le théorème suivant.Théorème 3 . Convergence de l’approximation polynomiale uniforme.1. Le processus de développement de f en série de polynômes de Tchebychev n’est pas stable, car 瑩p n 瑩 黎 1/Lgn . Mais il converge pour les fonctions telles que 諸f (1/n ) soit négligeable devant 1/Lgn , et d’autant plus rapidement que f est plus régulière.2. Ce processus est optimal parmi les processus consistants.3. En particulier, il n’existe pas de procédé d’approximation polynomiale uniforme à la fois consistant et stable. On notera que (face=F0021 暈([a , b ]), N size=1秊) étant complet, la convergence simple n’est même pas assurée.En outre, pour les fonctions suffisamment régulières, on peut remonter de l’approximation en moyenne quadratique à l’approximation uniforme. Il suffit pour cela de prouver que la série 見n (f )e n donnant le développement de f converge normalement sur l’intervalle considéré. En effet, dans ces conditions, s n (f ) converge uniformément vers une fonction continue g ; comme la convergence uniforme implique la convergence en moyenne quadratique sur un intervalle compact, s n (f ) converge aussi vers g en moyenne quadratique, et, par unicité de la limite, g = f . Pour établir la convergence normale, on majore 瑩e n 瑩 size=1秊 et on utilise le fait que, plus f est régulière, plus la suite ( 見n (f )) décroît rapidement.Le cas des séries de Fourier est bien classique: si f est continue et de classe C1 par morceaux, la série: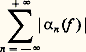 est convergente, ce qui assure la convergence normale de la série considérée puisque 瑩e n 瑩 size=1秊 = 1 (cf. séries TRIGONOMÉTRIQUES). On dispose de résultats analogues pour les développements en séries de polynômes orthogonaux (cf. polynômes ORTHOGONAUX). Dans le cas des développements en série de polynômes de Legendre, si f est continue et de classe C1 par morceaux sur [ 漣 1, + 1], la série 見n (f ) e n converge normalement sur tout compact de ] 漣 1, 1[ et si f est de classe C2, cette convergence est normale sur [ 漣 1, + 1]. Pour les développements en série de polynômes de Hermite, si f est continue et de classe C1 par morceaux sur R et si f et f sont de carré intégrable pour le poids 神, alors la convergence est normale sur tout compact de R.Cette même idée s’applique encore à l’étude de la convergence uniforme des développements en série de fonctions propres des équations de Sturm-Liouville (cf. équations DIFFÉRENTIELLES, chap. 3) ou des équations intégrales de Fredholm (cf. équations INTÉGRALES).Dans le même ordre d’idée, signalons le théorème de Rademacher-Menchov: si | 見n |2(Lg n )2 est fini, alors 見n e n converge vers f presque partout.Nous examinerons enfin le cas des processus interpolatoires.Théorème 4. Convergence des processus interpolatoires . Ici E = 暈([a , b ]) muni de N size=1秊. Soit S un système interpolateur sur [a , b ] et Ln le projecteur de E sur 戮n qui à tout élément f de E associe le polynôme d’interpolation de Lagrange (ou de Hermite) Ln (f ) (cf. chap. 5).1. Pour tout S, 瑩Ln 瑩 domine Lgn ; les processus interpolatoires ne sont donc ni stables ni convergents sur E.2. Si on prend pour S le système de Tchebychev, où [a , b ] = [ 漣 1, 1] et où 見j = cos[(2j + 1) 神/2n ] pour 0 諒 j 諒 n 漣 1, et Ln (f ) le polynôme d’interpolation de Lagrange associé à f , alors 瑩Ln 瑩 黎 Lgn . Autrement dit, l’interpolation de Tchebychev est sensiblement optimale parmi les processus consistants d’approximation polynomiale. En particulier, L n(f ) converge uniformément vers f dès que 諸f (1/n ) est négligeable devant 1/Lgn et, si f 捻 Lip size=1見,p :
est convergente, ce qui assure la convergence normale de la série considérée puisque 瑩e n 瑩 size=1秊 = 1 (cf. séries TRIGONOMÉTRIQUES). On dispose de résultats analogues pour les développements en séries de polynômes orthogonaux (cf. polynômes ORTHOGONAUX). Dans le cas des développements en série de polynômes de Legendre, si f est continue et de classe C1 par morceaux sur [ 漣 1, + 1], la série 見n (f ) e n converge normalement sur tout compact de ] 漣 1, 1[ et si f est de classe C2, cette convergence est normale sur [ 漣 1, + 1]. Pour les développements en série de polynômes de Hermite, si f est continue et de classe C1 par morceaux sur R et si f et f sont de carré intégrable pour le poids 神, alors la convergence est normale sur tout compact de R.Cette même idée s’applique encore à l’étude de la convergence uniforme des développements en série de fonctions propres des équations de Sturm-Liouville (cf. équations DIFFÉRENTIELLES, chap. 3) ou des équations intégrales de Fredholm (cf. équations INTÉGRALES).Dans le même ordre d’idée, signalons le théorème de Rademacher-Menchov: si | 見n |2(Lg n )2 est fini, alors 見n e n converge vers f presque partout.Nous examinerons enfin le cas des processus interpolatoires.Théorème 4. Convergence des processus interpolatoires . Ici E = 暈([a , b ]) muni de N size=1秊. Soit S un système interpolateur sur [a , b ] et Ln le projecteur de E sur 戮n qui à tout élément f de E associe le polynôme d’interpolation de Lagrange (ou de Hermite) Ln (f ) (cf. chap. 5).1. Pour tout S, 瑩Ln 瑩 domine Lgn ; les processus interpolatoires ne sont donc ni stables ni convergents sur E.2. Si on prend pour S le système de Tchebychev, où [a , b ] = [ 漣 1, 1] et où 見j = cos[(2j + 1) 神/2n ] pour 0 諒 j 諒 n 漣 1, et Ln (f ) le polynôme d’interpolation de Lagrange associé à f , alors 瑩Ln 瑩 黎 Lgn . Autrement dit, l’interpolation de Tchebychev est sensiblement optimale parmi les processus consistants d’approximation polynomiale. En particulier, L n(f ) converge uniformément vers f dès que 諸f (1/n ) est négligeable devant 1/Lgn et, si f 捻 Lip size=1見,p :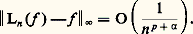 En revanche, si on prend des subdivisions à pas constant, 瑩Ln 瑩 croît exponentiellement, si bien que le processus peut fort bien diverger, même si f est analytique.GénéralisationsComme l’approximation polynomiale uniforme ne fonctionne pas bien, on est amené à choisir des fonctions un peu plus générales que les polynômes, à savoir polynomiales par morceaux.Le cas le plus simple est celui des fonctions affines par morceaux.Théorème 5 . Ici E = 暈([a , b ]) muni de N size=1秊. Soit Sn la subdivision de [a , b ] à pas constant (b 漣 a )/n et p n le projecteur de E sur le sous-espace vectoriel An des fonctions continues et affines sur chaque intervalle [t j , t j+1 ] de Sn . Alors le processus consistant (p n ) est stable car 瑩p n 瑩 = 1. En outre:
En revanche, si on prend des subdivisions à pas constant, 瑩Ln 瑩 croît exponentiellement, si bien que le processus peut fort bien diverger, même si f est analytique.GénéralisationsComme l’approximation polynomiale uniforme ne fonctionne pas bien, on est amené à choisir des fonctions un peu plus générales que les polynômes, à savoir polynomiales par morceaux.Le cas le plus simple est celui des fonctions affines par morceaux.Théorème 5 . Ici E = 暈([a , b ]) muni de N size=1秊. Soit Sn la subdivision de [a , b ] à pas constant (b 漣 a )/n et p n le projecteur de E sur le sous-espace vectoriel An des fonctions continues et affines sur chaque intervalle [t j , t j+1 ] de Sn . Alors le processus consistant (p n ) est stable car 瑩p n 瑩 = 1. En outre: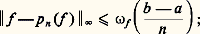 C’est pourquoi on peut alors recourir aux fonctions spline.Théorème 5 . Convergence de l’approximation par des fonctions spline . Soit encore Sn comme dans le théorème 5 et soit An ,3 l’espace vectoriel des fonctions spline cubiques associées à Sn et p n le projecteur de E sur An ,3 qui à tout f 捻 E associe la fonction spline cubique Sn (f ) interpolant f (cf. supra , chap. 5). Alors le processus consistant (p n ) est stable et:
C’est pourquoi on peut alors recourir aux fonctions spline.Théorème 5 . Convergence de l’approximation par des fonctions spline . Soit encore Sn comme dans le théorème 5 et soit An ,3 l’espace vectoriel des fonctions spline cubiques associées à Sn et p n le projecteur de E sur An ,3 qui à tout f 捻 E associe la fonction spline cubique Sn (f ) interpolant f (cf. supra , chap. 5). Alors le processus consistant (p n ) est stable et: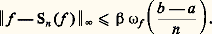 Cette fois, la rapidité de convergence est améliorée si f est plus régulière (jusqu’à la classe C4).Le cas des fonctions périodiques est entièrement analogue.Dans de nombreux problèmes, on s’intéresse à l’approximation de formes linéaires sur les espaces vectoriels de fonctions; ces questions étant intimement liées aux démarches de l’analyse numérique, nous renvoyons à l’article analyse NUMÉRIQUE. Il en est de même des méthodes d’accélération de convergence.
Cette fois, la rapidité de convergence est améliorée si f est plus régulière (jusqu’à la classe C4).Le cas des fonctions périodiques est entièrement analogue.Dans de nombreux problèmes, on s’intéresse à l’approximation de formes linéaires sur les espaces vectoriels de fonctions; ces questions étant intimement liées aux démarches de l’analyse numérique, nous renvoyons à l’article analyse NUMÉRIQUE. Il en est de même des méthodes d’accélération de convergence.
Encyclopédie Universelle. 2012.